 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSentence Pair Scoring: Towards Unified Framework for Text Comprehension
May 17, 2016
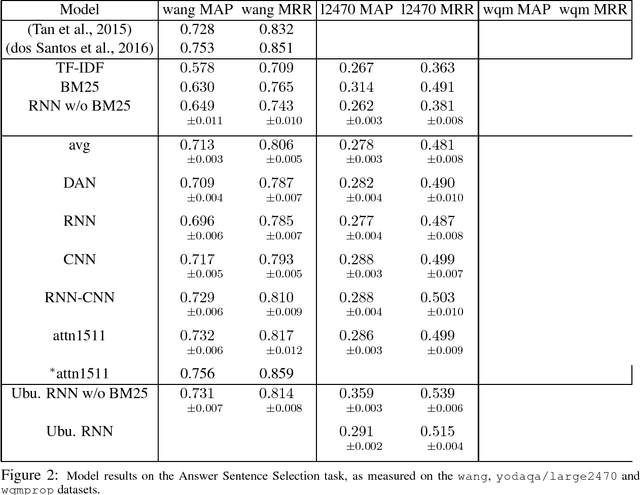
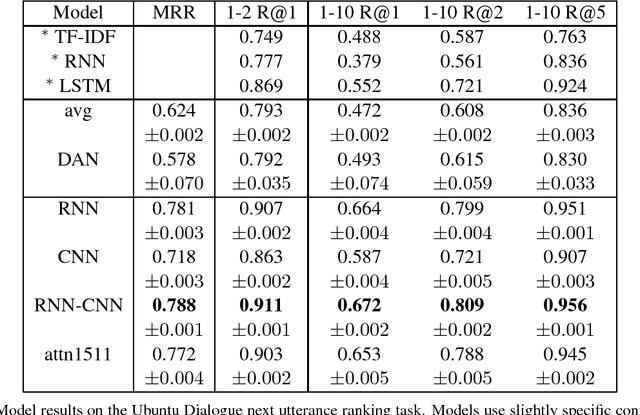
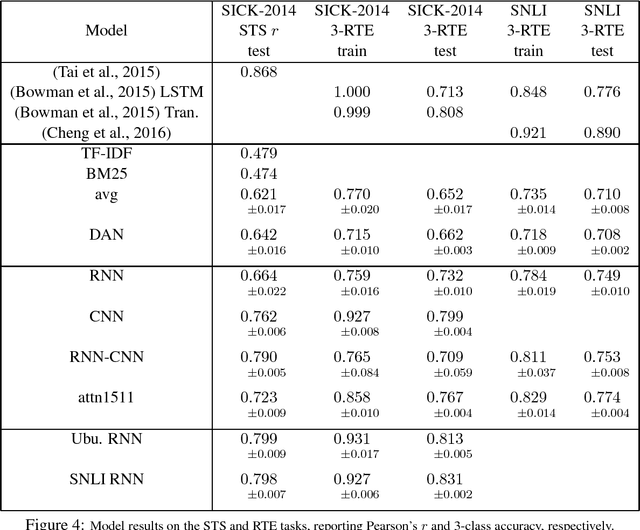
We review the task of Sentence Pair Scoring, popular in the literature in various forms - viewed as Answer Sentence Selection, Semantic Text Scoring, Next Utterance Ranking, Recognizing Textual Entailment, Paraphrasing or e.g. a component of Memory Networks. We argue that all such tasks are similar from the model perspective and propose new baselines by comparing the performance of common IR metrics and popular convolutional, recurrent and attention-based neural models across many Sentence Pair Scoring tasks and datasets. We discuss the problem of evaluating randomized models, propose a statistically grounded methodology, and attempt to improve comparisons by releasing new datasets that are much harder than some of the currently used well explored benchmarks. We introduce a unified open source software framework with easily pluggable models and tasks, which enables us to experiment with multi-task reusability of trained sentence model. We set a new state-of-art in performance on the Ubuntu Dialogue dataset.