 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-lingual Word Analogies using Linear Transformations between Semantic Spaces
Jul 11, 2018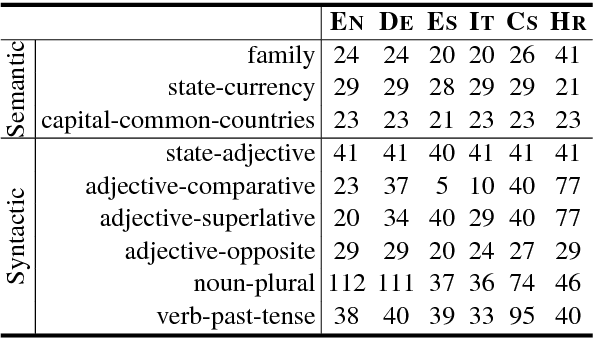
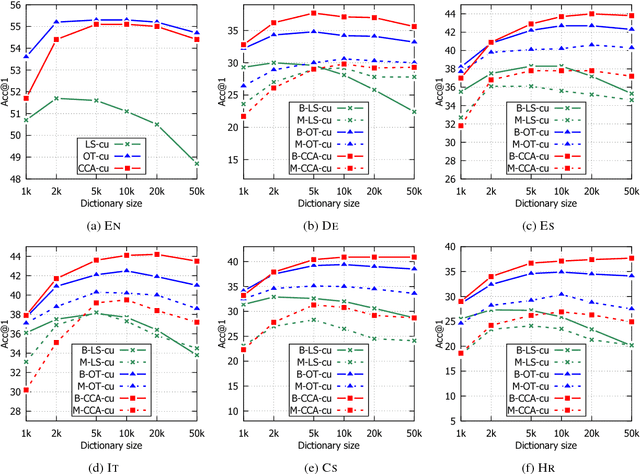
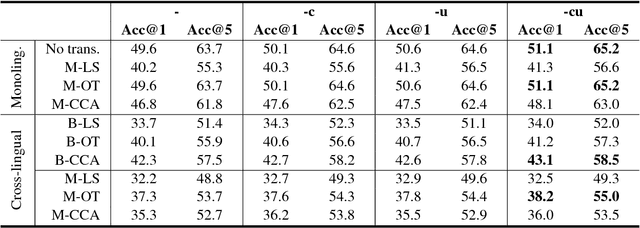
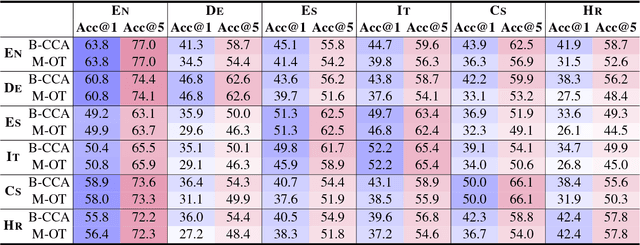
We generalize the word analogy task across languages, to provide a new intrinsic evaluation method for cross-lingual semantic spaces. We experiment with six languages within different language families, including English, German, Spanish, Italian, Czech, and Croatian. State-of-the-art monolingual semantic spaces are transformed into a shared space using dictionaries of word translations. We compare several linear transformations and rank them for experiments with monolingual (no transformation), bilingual (one semantic space is transformed to another), and multilingual (all semantic spaces are transformed onto English space) versions of semantic spaces. We show that tested linear transformations preserve relationships between words (word analogies) and lead to impressive results. We achieve average accuracy of 51.1%, 43.1%, and 38.2% for monolingual, bilingual, and multilingual semantic spaces, respectively.
Linear Transformations for Cross-lingual Semantic Textual Similarity
Jul 11, 2018



Cross-lingual semantic textual similarity systems estimate the degree of the meaning similarity between two sentences, each in a different language. State-of-the-art algorithms usually employ machine translation and combine vast amount of features, making the approach strongly supervised, resource rich, and difficult to use for poorly-resourced languages. In this paper, we study linear transformations, which project monolingual semantic spaces into a shared space using bilingual dictionaries. We propose a novel transformation, which builds on the best ideas from prior works. We experiment with unsupervised techniques for sentence similarity based only on semantic spaces and we show they can be significantly improved by the word weighting. Our transformation outperforms other methods and together with word weighting leads to very promising results on several datasets in different languages.
Unsupervised Dialogue Act Induction using Gaussian Mixtures
Feb 08, 2017

This paper introduces a new unsupervised approach for dialogue act induction. Given the sequence of dialogue utterances, the task is to assign them the labels representing their function in the dialogue. Utterances are represented as real-valued vectors encoding their meaning. We model the dialogue as Hidden Markov model with emission probabilities estimated by Gaussian mixtures. We use Gibbs sampling for posterior inference. We present the results on the standard Switchboard-DAMSL corpus. Our algorithm achieves promising results compared with strong supervised baselines and outperforms other unsupervised algorithms.
New word analogy corpus for exploring embeddings of Czech words
Aug 02, 2016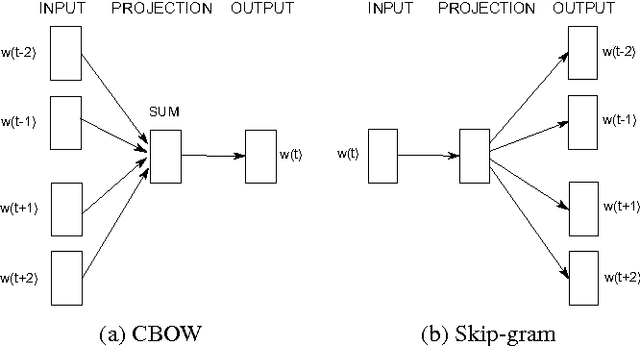
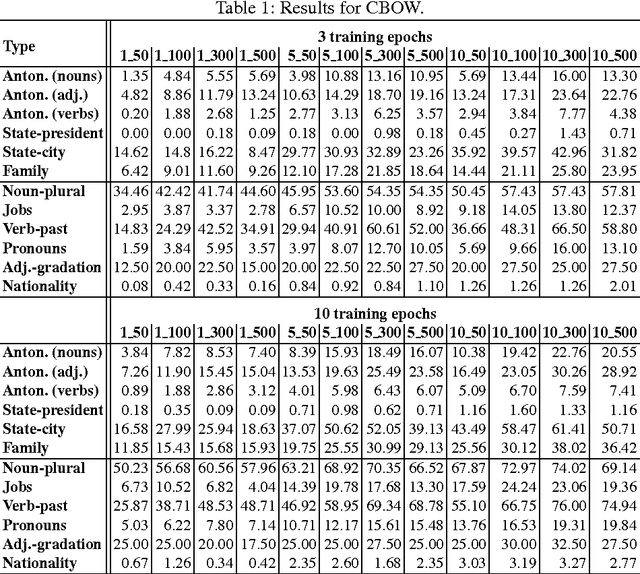
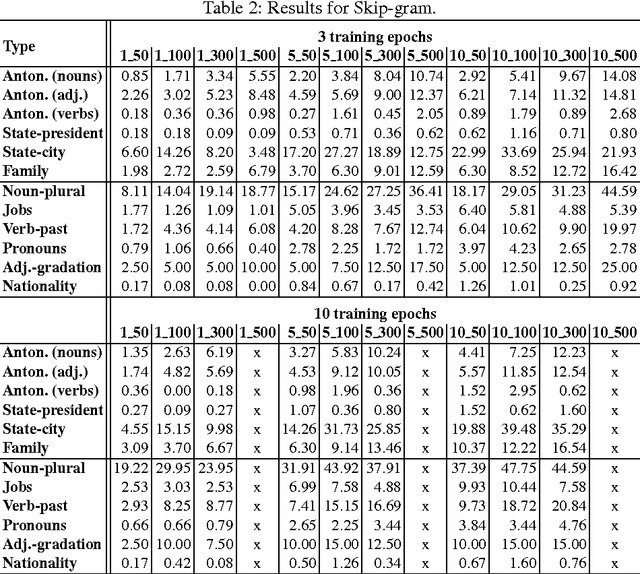
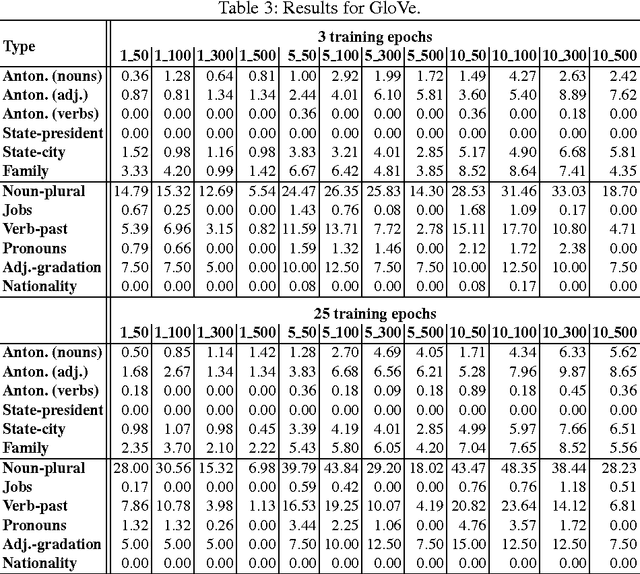
The word embedding methods have been proven to be very useful in many tasks of NLP (Natural Language Processing). Much has been investigated about word embeddings of English words and phrases, but only little attention has been dedicated to other languages. Our goal in this paper is to explore the behavior of state-of-the-art word embedding methods on Czech, the language that is characterized by very rich morphology. We introduce new corpus for word analogy task that inspects syntactic, morphosyntactic and semantic properties of Czech words and phrases. We experiment with Word2Vec and GloVe algorithms and discuss the results on this corpus. The corpus is available for the research community.