 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-lingual Word Analogies using Linear Transformations between Semantic Spaces
Jul 11, 2018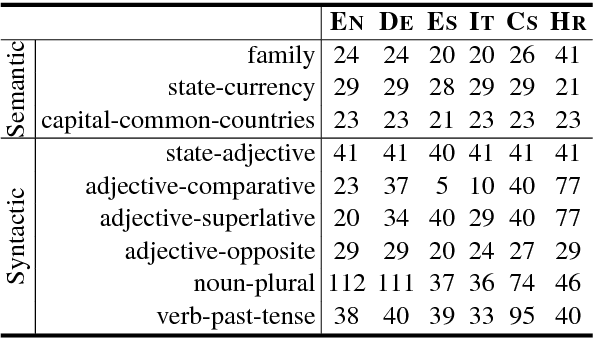
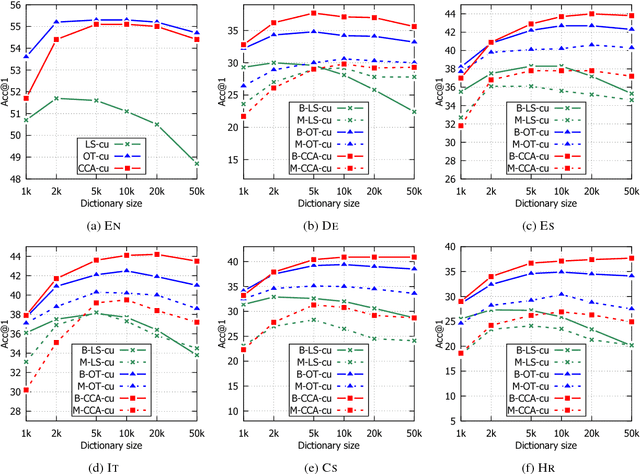
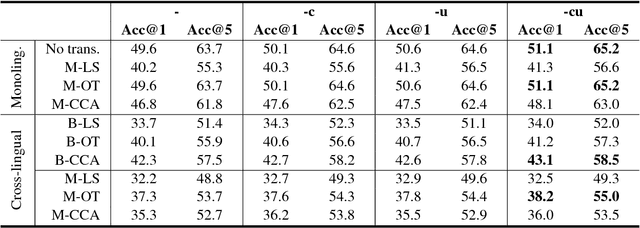
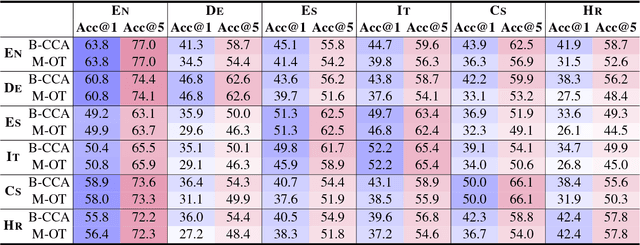
We generalize the word analogy task across languages, to provide a new intrinsic evaluation method for cross-lingual semantic spaces. We experiment with six languages within different language families, including English, German, Spanish, Italian, Czech, and Croatian. State-of-the-art monolingual semantic spaces are transformed into a shared space using dictionaries of word translations. We compare several linear transformations and rank them for experiments with monolingual (no transformation), bilingual (one semantic space is transformed to another), and multilingual (all semantic spaces are transformed onto English space) versions of semantic spaces. We show that tested linear transformations preserve relationships between words (word analogies) and lead to impressive results. We achieve average accuracy of 51.1%, 43.1%, and 38.2% for monolingual, bilingual, and multilingual semantic spaces, respectively.
New word analogy corpus for exploring embeddings of Czech words
Aug 02, 2016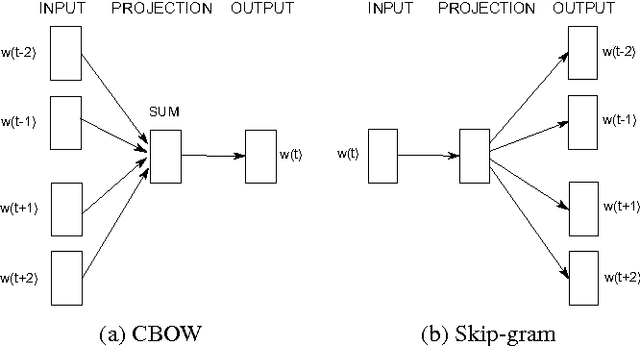
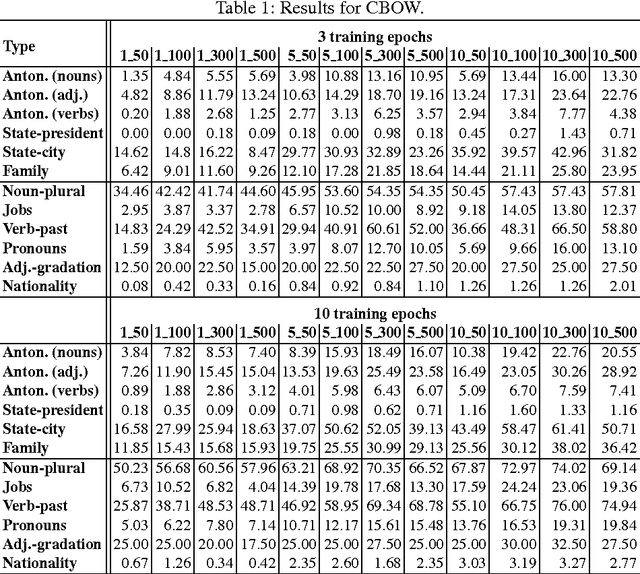
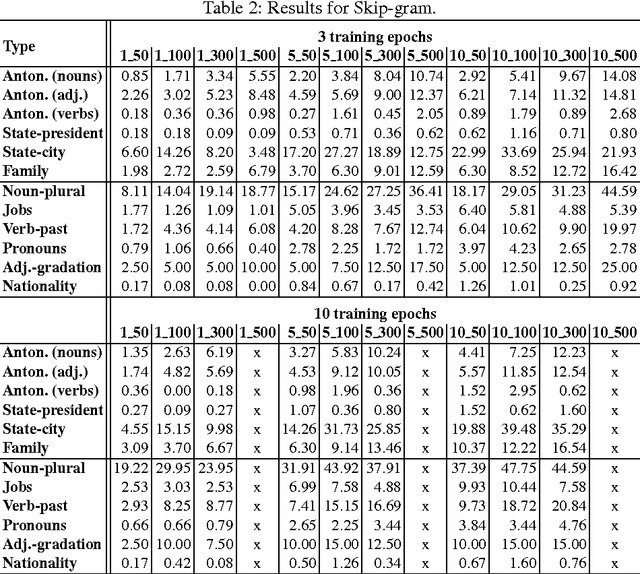
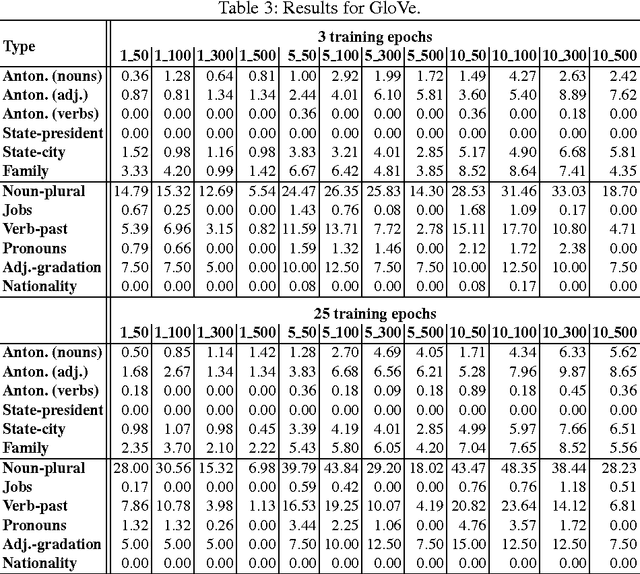
The word embedding methods have been proven to be very useful in many tasks of NLP (Natural Language Processing). Much has been investigated about word embeddings of English words and phrases, but only little attention has been dedicated to other languages. Our goal in this paper is to explore the behavior of state-of-the-art word embedding methods on Czech, the language that is characterized by very rich morphology. We introduce new corpus for word analogy task that inspects syntactic, morphosyntactic and semantic properties of Czech words and phrases. We experiment with Word2Vec and GloVe algorithms and discuss the results on this corpus. The corpus is available for the research community.