 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning using granularity statistical invariants for classification
Mar 29, 2024
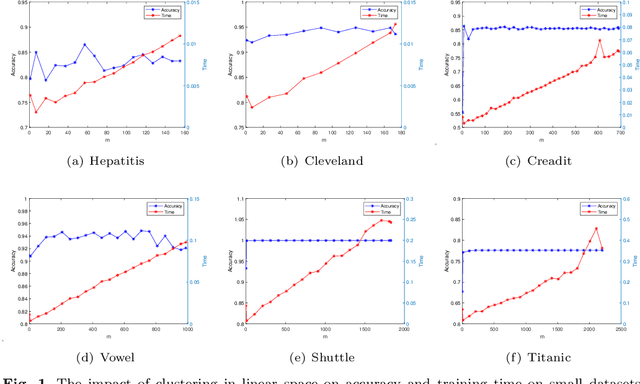


Learning using statistical invariants (LUSI) is a new learning paradigm, which adopts weak convergence mechanism, and can be applied to a wider range of classification problems. However, the computation cost of invariant matrices in LUSI is high for large-scale datasets during training. To settle this issue, this paper introduces a granularity statistical invariant for LUSI, and develops a new learning paradigm called learning using granularity statistical invariants (LUGSI). LUGSI employs both strong and weak convergence mechanisms, taking a perspective of minimizing expected risk. As far as we know, it is the first time to construct granularity statistical invariants. Compared to LUSI, the introduction of this new statistical invariant brings two advantages. Firstly, it enhances the structural information of the data. Secondly, LUGSI transforms a large invariant matrix into a smaller one by maximizing the distance between classes, achieving feasibility for large-scale datasets classification problems and significantly enhancing the training speed of model operations. Experimental results indicate that LUGSI not only exhibits improved generalization capabilities but also demonstrates faster training speed, particularly for large-scale datasets.