 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo Large Language Models understand Medical Codes?
Mar 21, 2024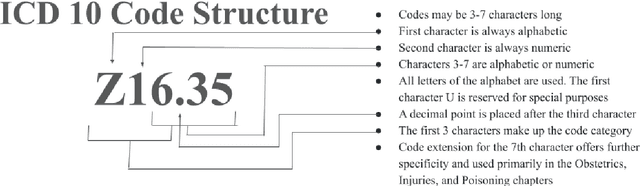
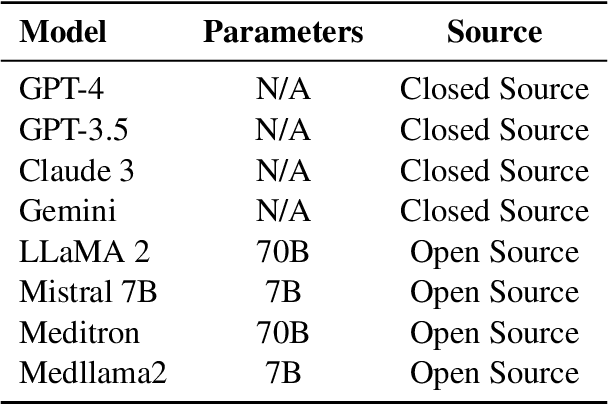
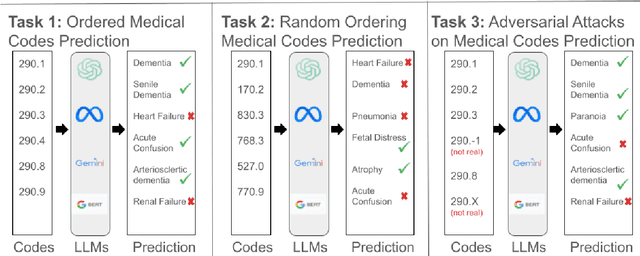

The overarching goal of recent AI research has been to make steady progress towards achieving Artificial General Intelligence (AGI), prompting the evaluation of Large Language Models (LLMs) across a variety of tasks and domains. One such domain is healthcare, where LLMs can greatly benefit clinical practice by assisting with a wide range of tasks. However, these models are also prone to producing ``hallucinations" or incorrect responses when faced with queries they cannot adequately address, raising concerns and skepticism, especially within the healthcare community. In this work, we investigate whether LLMs understand and can predict medical codes, which are extensively utilized in healthcare practice. This study aims to delineate the capabilities and limitations of these LLMs. We evaluate various off-the-shelf LLMs (e.g., GPT, LLaMA, etc.) and LLMs specifically designed for biomedical applications to assess their awareness and understanding of these domain-specific terminologies. Our results indicate that these models as they currently stand do not comprehend the meaning of the medical codes, highlighting the need for better representation of these alphanumeric codes extensively used in healthcare. We call for improved strategies to effectively capture and represent the nuances of medical codes and terminologies within LLMs, enabling them to become more reliable and trustworthy tools for healthcare professionals.