 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePerplexed by Quality: A Perplexity-based Method for Adult and Harmful Content Detection in Multilingual Heterogeneous Web Data
Dec 20, 2022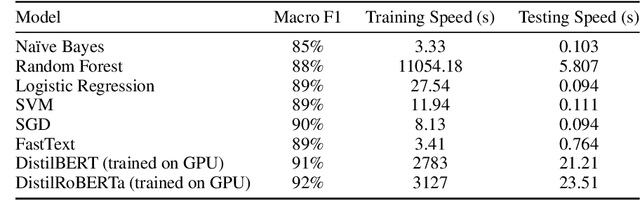
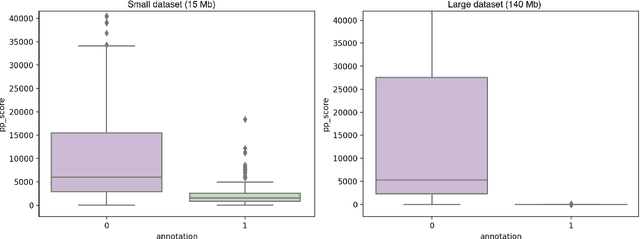
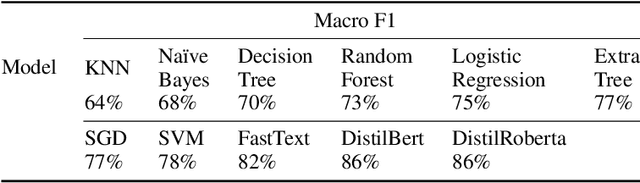
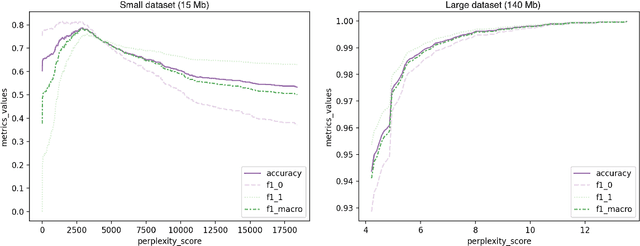
As demand for large corpora increases with the size of current state-of-the-art language models, using web data as the main part of the pre-training corpus for these models has become a ubiquitous practice. This, in turn, has introduced an important challenge for NLP practitioners, as they are now confronted with the task of developing highly optimized models and pipelines for pre-processing large quantities of textual data, which implies, effectively classifying and filtering multilingual, heterogeneous and noisy data, at web scale. One of the main components of this pre-processing step for the pre-training corpora of large language models, is the removal of adult and harmful content. In this paper we explore different methods for detecting adult and harmful of content in multilingual heterogeneous web data. We first show how traditional methods in harmful content detection, that seemingly perform quite well in small and specialized datasets quickly break down when confronted with heterogeneous noisy web data. We then resort to using a perplexity based approach but with a twist: Instead of using a so-called "clean" corpus to train a small language model and then use perplexity so select the documents with low perplexity, i.e., the documents that resemble this so-called "clean" corpus the most. We train solely with adult and harmful textual data, and then select the documents having a perplexity value above a given threshold. This approach will virtually cluster our documents into two distinct groups, which will greatly facilitate the choice of the threshold for the perplexity and will also allow us to obtain higher precision than with the traditional classification methods for detecting adult and harmful content.