 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNNN: Next-Generation Neural Networks for Marketing Mix Modeling
Apr 09, 2025



We present NNN, a Transformer-based neural network approach to Marketing Mix Modeling (MMM) designed to address key limitations of traditional methods. Unlike conventional MMMs which rely on scalar inputs and parametric decay functions, NNN uses rich embeddings to capture both quantitative and qualitative aspects of marketing and organic channels (e.g., search queries, ad creatives). This, combined with its attention mechanism, enables NNN to model complex interactions, capture long-term effects, and potentially improve sales attribution accuracy. We show that L1 regularization permits the use of such expressive models in typical data-constrained settings. Evaluating NNN on simulated and real-world data demonstrates its efficacy, particularly through considerable improvement in predictive power. Beyond attribution, NNN provides valuable, complementary insights through model probing, such as evaluating keyword or creative effectiveness, enhancing model interpretability.
Compressing Search with Language Models
Jun 24, 2024



Millions of people turn to Google Search each day for information on things as diverse as new cars or flu symptoms. The terms that they enter contain valuable information on their daily intent and activities, but the information in these search terms has been difficult to fully leverage. User-defined categorical filters have been the most common way to shrink the dimensionality of search data to a tractable size for analysis and modeling. In this paper we present a new approach to reducing the dimensionality of search data while retaining much of the information in the individual terms without user-defined rules. Our contributions are two-fold: 1) we introduce SLaM Compression, a way to quantify search terms using pre-trained language models and create a representation of search data that has low dimensionality, is memory efficient, and effectively acts as a summary of search, and 2) we present CoSMo, a Constrained Search Model for estimating real world events using only search data. We demonstrate the efficacy of our contributions by estimating with high accuracy U.S. automobile sales and U.S. flu rates using only Google Search data.
Q-Match: Self-Supervised Learning by Matching Distributions Induced by a Queue
Feb 22, 2023



In semi-supervised learning, student-teacher distribution matching has been successful in improving performance of models using unlabeled data in conjunction with few labeled samples. In this paper, we aim to replicate that success in the self-supervised setup where we do not have access to any labeled data during pre-training. We introduce our algorithm, Q-Match, and show it is possible to induce the student-teacher distributions without any knowledge of downstream classes by using a queue of embeddings of samples from the unlabeled dataset. We focus our study on tabular datasets and show that Q-Match outperforms previous self-supervised learning techniques when measuring downstream classification performance. Furthermore, we show that our method is sample efficient--in terms of both the labels required for downstream training and the amount of unlabeled data required for pre-training--and scales well to the sizes of both the labeled and unlabeled data.
CSS10: A Collection of Single Speaker Speech Datasets for 10 Languages
Apr 03, 2019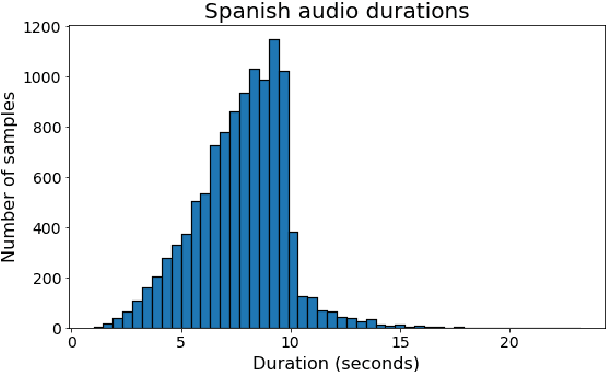


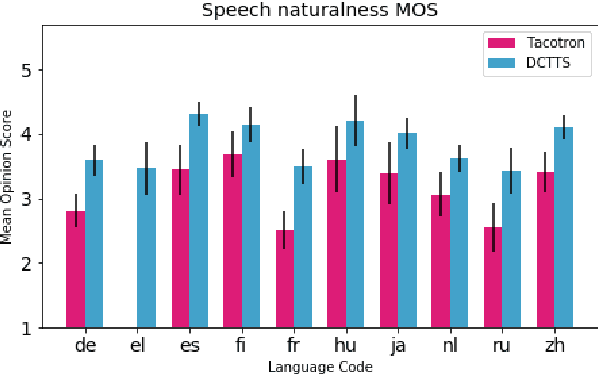
We describe our development of CSS10, a collection of single speaker speech datasets for ten languages. It is composed of short audio clips from LibriVox audiobooks and their aligned texts. To validate its quality we train two neural text-to-speech models on each dataset. Subsequently, we conduct Mean Opinion Score tests on the synthesized speech samples. We make our datasets, pre-trained models, and test resources publicly available. We hope they will be used for future speech tasks.