 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Bi-gram Graph Attributes
Jul 05, 2021


We propose a new approach to text semantic analysis and general corpus analysis using, as termed in this article, a "bi-gram graph" representation of a corpus. The different attributes derived from graph theory are measured and analyzed as unique insights or against other corpus graphs. We observe a vast domain of tools and algorithms that can be developed on top of the graph representation; creating such a graph proves to be computationally cheap, and much of the heavy lifting is achieved via basic graph calculations. Furthermore, we showcase the different use-cases for the bi-gram graphs and how scalable it proves to be when dealing with large datasets.
A New Approach To Text Rating Classification Using Sentiment Analysis
Mar 31, 2021
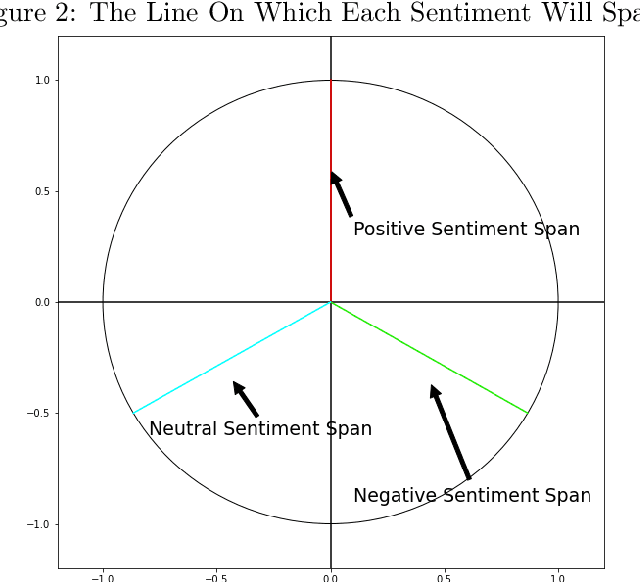
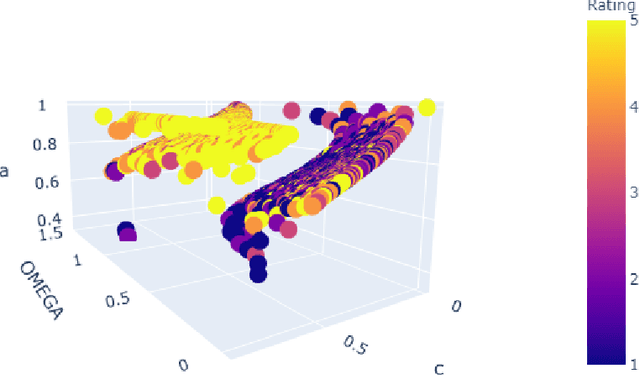
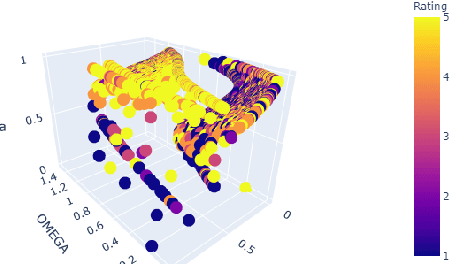
Typical use cases of sentiment analysis usually revolve around assessing the probability of a text belonging to a certain sentiment and deriving insight concerning it; little work has been done to explore further use cases derived using those probabilities in the context of rating. In this paper, we redefine the sentiment proportion values as building blocks for a triangle structure, allowing us to derive variables for a new formula for classifying text given in the form of product reviews into a group of higher and a group of lower ratings and prove a dependence exists between the sentiments and the ratings.