 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA New Spatio-Temporal Loss Function for 3D Motion Reconstruction and Extended Temporal Metrics for Motion Evaluation
Oct 16, 2022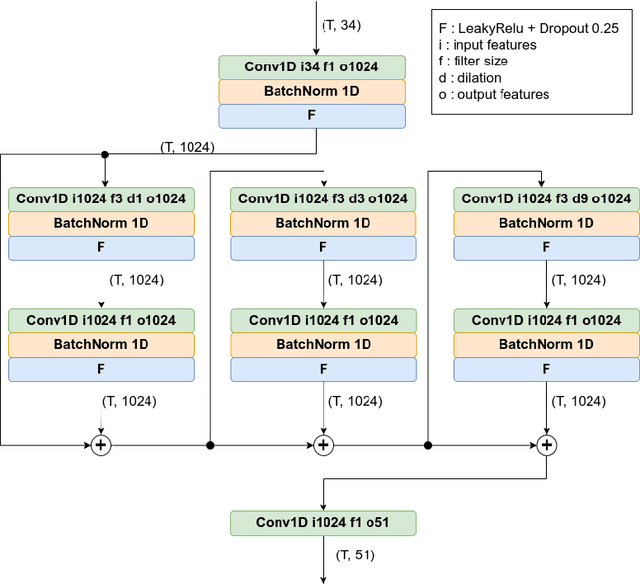

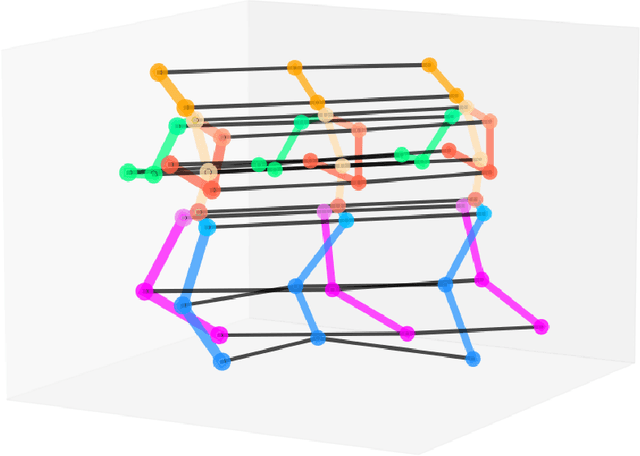

We propose a new loss function that we call Laplacian loss, based on spatio-temporal Laplacian representation of the motion as a graph. This loss function is intended to be used in training models for motion reconstruction through 3D human pose estimation from videos. It compares the differential coordinates of the joints obtained from the graph representation of the ground truth against the one of the estimation. We design a fully convolutional temporal network for motion reconstruction to achieve better temporal consistency of estimation. We use this generic model to study the impact of our proposed loss function on the benchmarks provided by Human3.6M. We also make use of various motion descriptors such as velocity, acceleration to make a thorough evaluation of the temporal consistency while comparing the results to some of the state-of-the-art solutions.