 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnbiased split variable selection for random survival forests using maximally selected rank statistics
May 16, 2018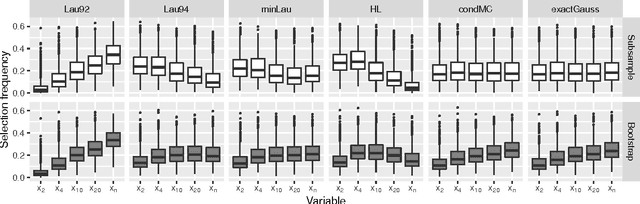

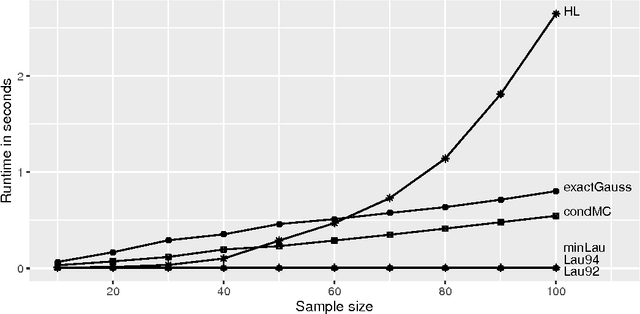

The most popular approach for analyzing survival data is the Cox regression model. The Cox model may, however, be misspecified, and its proportionality assumption may not always be fulfilled. An alternative approach for survival prediction is random forests for survival outcomes. The standard split criterion for random survival forests is the log-rank test statistics, which favors splitting variables with many possible split points. Conditional inference forests avoid this split variable selection bias. However, linear rank statistics are utilized by default in conditional inference forests to select the optimal splitting variable, which cannot detect non-linear effects in the independent variables. An alternative is to use maximally selected rank statistics for the split point selection. As in conditional inference forests, splitting variables are compared on the p-value scale. However, instead of the conditional Monte-Carlo approach used in conditional inference forests, p-value approximations are employed. We describe several p-value approximations and the implementation of the proposed random forest approach. A simulation study demonstrates that unbiased split variable selection is possible. However, there is a trade-off between unbiased split variable selection and runtime. In benchmark studies of prediction performance on simulated and real datasets the new method performs better than random survival forests if informative dichotomous variables are combined with uninformative variables with more categories and better than conditional inference forests if non-linear covariate effects are included. In a runtime comparison the method proves to be computationally faster than both alternatives, if a simple p-value approximation is used.