 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast-MWEM: Private Data Release in Sublinear Time
Feb 03, 2026The Multiplicative Weights Exponential Mechanism (MWEM) is a fundamental iterative framework for private data analysis, with broad applications such as answering $m$ linear queries, or privately solving systems of $m$ linear constraints. However, a critical bottleneck hindering its scalability is the $Θ(m)$ time complexity required to execute the exponential mechanism in each iteration. We introduce a modification to the MWEM framework that improves the per-iteration runtime dependency to $Θ(\sqrt{m})$ in expectation. This is done via a lazy sampling approach to the Report-Noisy-Max mechanism, which we implement efficiently using Gumbel noise and a $k$-Nearest Neighbor data structure. This allows for the rapid selection of the approximate score in the exponential mechanism without an exhaustive linear scan. We apply our accelerated framework to the problems of private linear query release and solving Linear Programs (LPs) under neighboring constraint conditions and low-sensitivity assumptions. Experimental evaluation confirms that our method provides a substantial runtime improvement over classic MWEM.
Compression Barriers for Autoregressive Transformers
Feb 21, 2025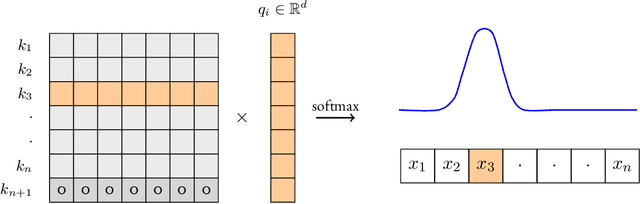
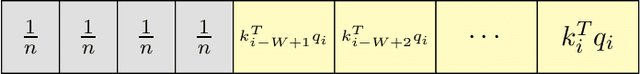
A key limitation of autoregressive Transformers is the large memory needed at inference-time to cache all previous key-value (KV) embeddings. Prior works address this by compressing the KV cache, but often assume specific structural properties of the embeddings. This raises the following natural question: Can truly sublinear space utilization be achieved without such assumptions? In this work, we answer this question in the negative. Any algorithm for attention-based token generation must use $\Theta(nd)$ space, where $n$ is the number of tokens generated so far and $d = \Omega(\log n)$ is the dimension of the KV embeddings. Our proof involves a reduction from a classic communication complexity problem and uses a randomized construction that leverages properties of projections in the spirit of the Johnson-Linderstrauss lemma. For the low-dimensional regime $d = o(\log n)$, we show that any algorithm requires $\Omega(d\cdot e^d)$ space and prove, using tight bounds on covering numbers, that SubGen, proposed by Zandieh, Han, Mirrokni and Karbasi, matches this bound. Further, we investigate how sparsity assumptions enable token generation in truly sublinear space, presenting impossibility results and proposing a new KV cache compression algorithm for sliding window attention when the value cache outside the window is unmasked. Finally, we analyze token generation's time complexity, using an indistinguishability argument to prove that no non-adaptive algorithm can compute attention online in sublinear time for all tokens.
$k$NN Attention Demystified: A Theoretical Exploration for Scalable Transformers
Nov 06, 2024



Despite their power, Transformers face challenges with long sequences due to the quadratic complexity of self-attention. To address this limitation, methods like $k$-Nearest-Neighbor ($k$NN) attention have been introduced [Roy, Saffar, Vaswani, Grangier, 2021] enabling each token to attend to only its $k$ closest tokens. While $k$NN attention has shown empirical success in making Transformers more efficient, its exact approximation guarantees have not been theoretically analyzed. In this work, we establish a theoretical framework for $k$NN attention, reformulating self-attention as expectations over softmax distributions and leveraging lazy Gumbel sampling [Mussmann, Levy, Ermon, 2017] with $k$NN indices for efficient approximation. Building on this framework, we also propose novel sub-quadratic algorithms that approximate self-attention gradients by leveraging efficient sampling techniques, such as Markov Chain-based estimation. Finally, we demonstrate the practical effectiveness of these algorithms through empirical experiments, showcasing their benefits in both training and inference.