 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompression Barriers for Autoregressive Transformers
Paper and Code
Feb 21, 2025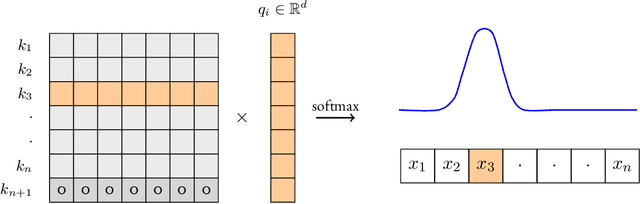
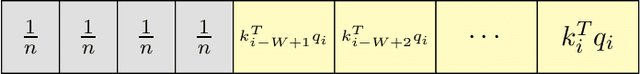
A key limitation of autoregressive Transformers is the large memory needed at inference-time to cache all previous key-value (KV) embeddings. Prior works address this by compressing the KV cache, but often assume specific structural properties of the embeddings. This raises the following natural question: Can truly sublinear space utilization be achieved without such assumptions? In this work, we answer this question in the negative. Any algorithm for attention-based token generation must use $\Theta(nd)$ space, where $n$ is the number of tokens generated so far and $d = \Omega(\log n)$ is the dimension of the KV embeddings. Our proof involves a reduction from a classic communication complexity problem and uses a randomized construction that leverages properties of projections in the spirit of the Johnson-Linderstrauss lemma. For the low-dimensional regime $d = o(\log n)$, we show that any algorithm requires $\Omega(d\cdot e^d)$ space and prove, using tight bounds on covering numbers, that SubGen, proposed by Zandieh, Han, Mirrokni and Karbasi, matches this bound. Further, we investigate how sparsity assumptions enable token generation in truly sublinear space, presenting impossibility results and proposing a new KV cache compression algorithm for sliding window attention when the value cache outside the window is unmasked. Finally, we analyze token generation's time complexity, using an indistinguishability argument to prove that no non-adaptive algorithm can compute attention online in sublinear time for all tokens.