 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTwo-terminal source coding with common sum reconstruction
Jun 14, 2022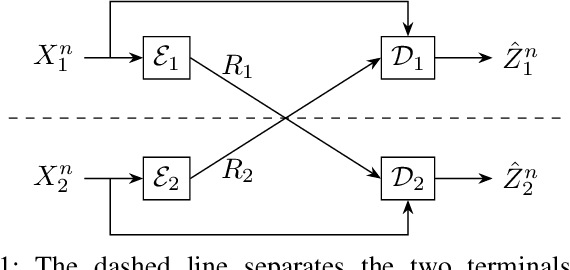

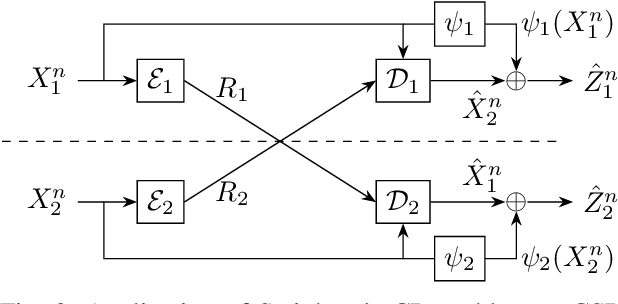
We present the problem of two-terminal source coding with Common Sum Reconstruction (CSR). Consider two terminals, each with access to one of two correlated sources. Both terminals want to reconstruct the sum of the two sources under some average distortion constraint, and the reconstructions at two terminals must be identical with high probability. In this paper, we develop inner and outer bounds to the achievable rate distortion region of the CSR problem for a doubly symmetric binary source. We employ existing achievability results for Steinberg's common reconstruction and Wyner-Ziv's source coding with side information problems, and an achievability result for the lossy version of Korner-Marton's modulo-two sum computation problem.
Decentralized optimization with non-identical sampling in presence of stragglers
Aug 25, 2021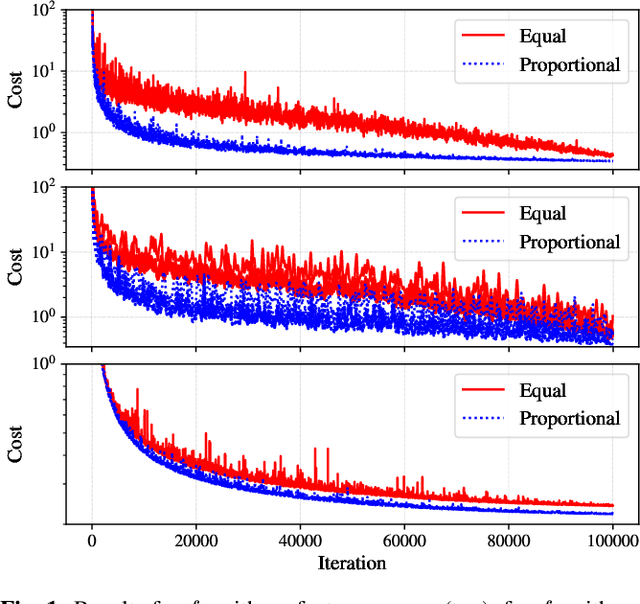
We consider decentralized consensus optimization when workers sample data from non-identical distributions and perform variable amounts of work due to slow nodes known as stragglers. The problem of non-identical distributions and the problem of variable amount of work have been previously studied separately. In our work we analyze them together under a unified system model. We study the convergence of the optimization algorithm when combining worker outputs under two heuristic methods: (1) weighting equally, and (2) weighting by the amount of work completed by each. We prove convergence of the two methods under perfect consensus, assuming straggler statistics are independent and identical across all workers for all iterations. Our numerical results show that under approximate consensus the second method outperforms the first method for both convex and non-convex objective functions. We make use of the theory on minimum variance unbiased estimator (MVUE) to evaluate the existence of an optimal method for combining worker outputs. While we conclude that neither of the two heuristic methods are optimal, we also show that an optimal method does not exist.
Rate distortion comparison of a few gradient quantizers
Aug 23, 2021



This article is in the context of gradient compression. Gradient compression is a popular technique for mitigating the communication bottleneck observed when training large machine learning models in a distributed manner using gradient-based methods such as stochastic gradient descent. In this article, assuming a Gaussian distribution for the components in gradient, we find the rate distortion trade-off of gradient quantization schemes such as Scaled-sign and Top-K, and compare with the Shannon rate distortion limit. A similar comparison with vector quantizers also is presented.
Efficient learning of neighbor representations for boundary trees and forests
Oct 26, 2018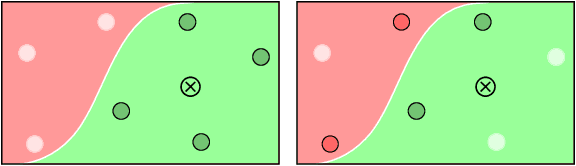


We introduce a semiparametric approach to neighbor-based classification. We build off the recently proposed Boundary Trees algorithm by Mathy et al.(2015) which enables fast neighbor-based classification, regression and retrieval in large datasets. While boundary trees use an Euclidean measure of similarity, the Differentiable Boundary Tree algorithm by Zoran et al.(2017) was introduced to learn low-dimensional representations of complex input data, on which semantic similarity can be calculated to train boundary trees. As is pointed out by its authors, the differentiable boundary tree approach contains a few limitations that prevents it from scaling to large datasets. In this paper, we introduce Differentiable Boundary Sets, an algorithm that overcomes the computational issues of the differentiable boundary tree scheme and also improves its classification accuracy and data representability. Our algorithm is efficiently implementable with existing tools and offers a significant reduction in training time. We test and compare the algorithms on the well known MNIST handwritten digits dataset and the newer Fashion-MNIST dataset by Xiao et al.(2017).