 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Scale and Rotational Invariant Key-point Detector based on Sparse Coding
Oct 13, 2020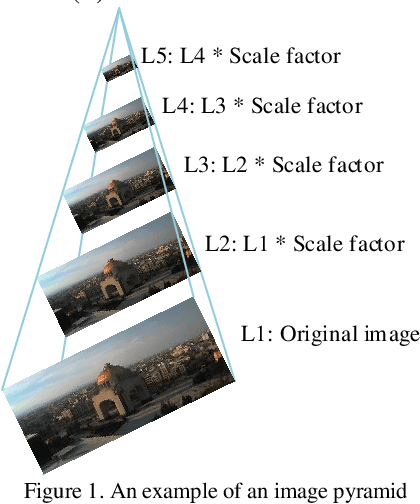
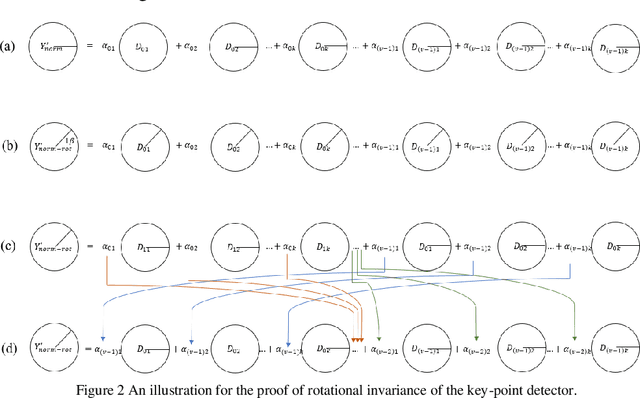


Most popular hand-crafted key-point detectors such as Harris corner, SIFT, SURF aim to detect corners, blobs, junctions or other human defined structures in images. Though being robust with some geometric transformations, unintended scenarios or non-uniform lighting variations could significantly degrade their performance. Hence, a new detector that is flexible with context change and simultaneously robust with both geometric and non-uniform illumination variations is very desirable. In this paper, we propose a solution to this challenging problem by incorporating Scale and Rotation Invariant design (named SRI-SCK) into a recently developed Sparse Coding based Key-point detector (SCK). The SCK detector is flexible in different scenarios and fully invariant to affine intensity change, yet it is not designed to handle images with drastic scale and rotation changes. In SRI-SCK, the scale invariance is implemented with an image pyramid technique while the rotation invariance is realized by combining multiple rotated versions of the dictionary used in the sparse coding step of SCK. Techniques for calculation of key-points' characteristic scales and their sub-pixel accuracy positions are also proposed. Experimental results on three public datasets demonstrate that significantly high repeatability and matching score are achieved.
SCK: A sparse coding based key-point detector
Sep 26, 2018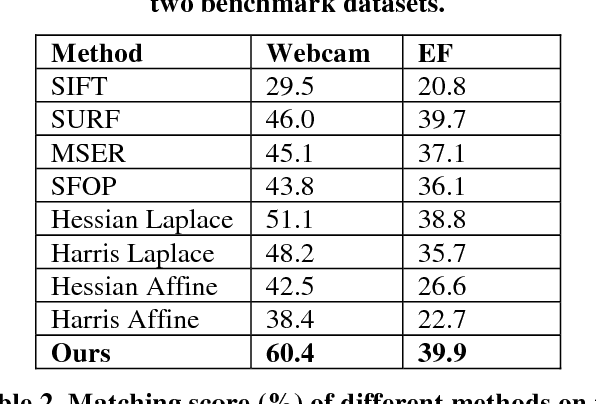
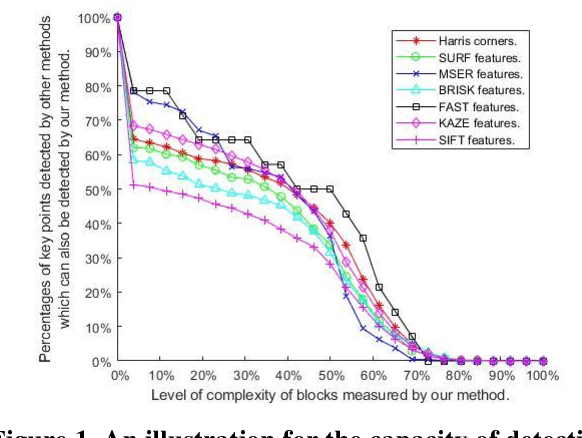
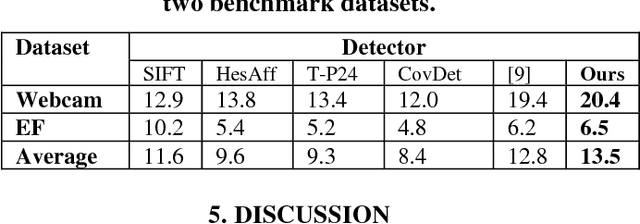

All current popular hand-crafted key-point detectors such as Harris corner, MSER, SIFT, SURF... rely on some specific pre-designed structures for the detection of corners, blobs, or junctions in an image. In this paper, a novel sparse coding based key-point detector which requires no particular pre-designed structures is presented. The key-point detector is based on measuring the complexity level of each block in an image to decide where a key-point should be. The complexity level of a block is defined as the total number of non-zero components of a sparse representation of that block. Generally, a block constructed with more components is more complex and has greater potential to be a good key-point. Experimental results on Webcam and EF datasets [1, 2] show that the proposed detector achieves significantly high repeatability compared to hand-crafted features, and even outperforms the matching scores of the state-of-the-art learning based detector.
* Manuscript accepted for presentation at 2018 IEEE International Conference on Image Processing, October 7-10, 2018, Athens, Greece. Patent applied. If you use any techniques, claims, images in this manuscript, please cite the corresponding paper