 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnomaly Detection in Bitcoin Network Using Unsupervised Learning Methods
Feb 25, 2017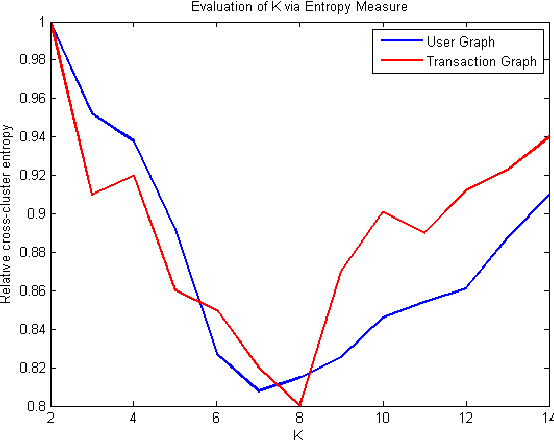
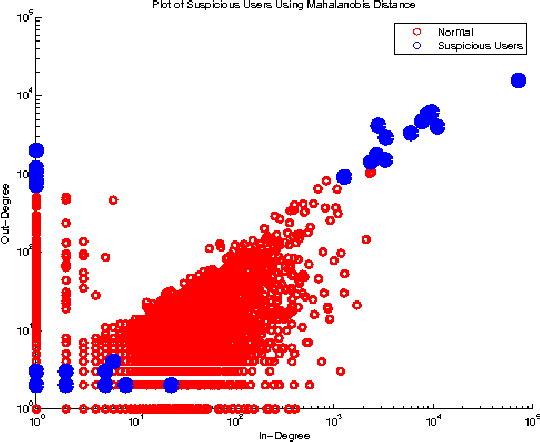
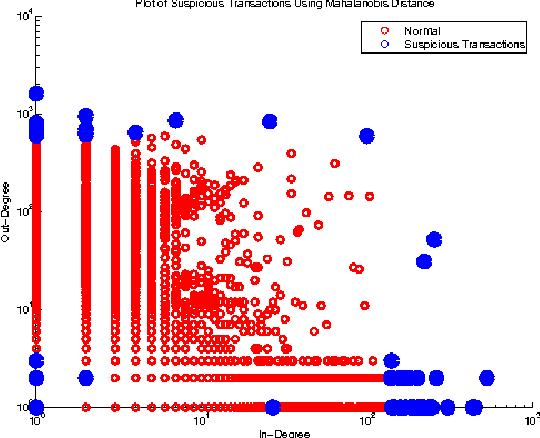
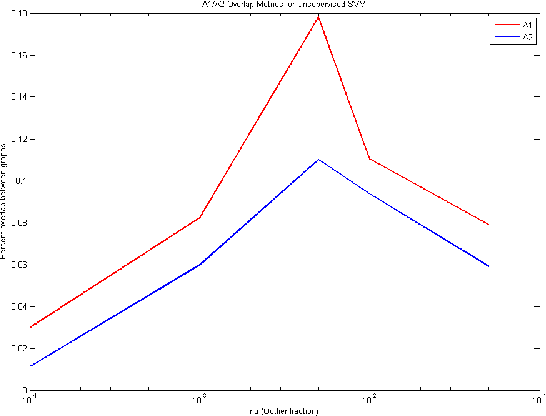
The problem of anomaly detection has been studied for a long time. In short, anomalies are abnormal or unlikely things. In financial networks, thieves and illegal activities are often anomalous in nature. Members of a network want to detect anomalies as soon as possible to prevent them from harming the network's community and integrity. Many Machine Learning techniques have been proposed to deal with this problem; some results appear to be quite promising but there is no obvious superior method. In this paper, we consider anomaly detection particular to the Bitcoin transaction network. Our goal is to detect which users and transactions are the most suspicious; in this case, anomalous behavior is a proxy for suspicious behavior. To this end, we use three unsupervised learning methods including k-means clustering, Mahalanobis distance, and Unsupervised Support Vector Machine (SVM) on two graphs generated by the Bitcoin transaction network: one graph has users as nodes, and the other has transactions as nodes.
Low Latency Anomaly Detection and Bayesian Network Prediction of Anomaly Likelihood
Nov 11, 2016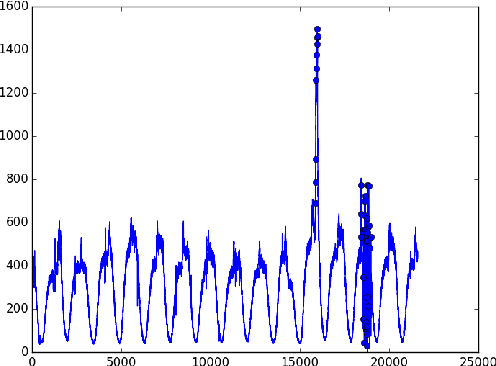
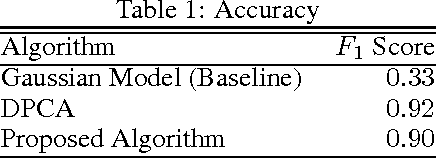
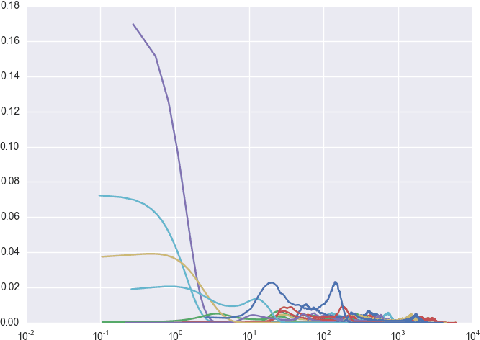

We develop a supervised machine learning model that detects anomalies in systems in real time. Our model processes unbounded streams of data into time series which then form the basis of a low-latency anomaly detection model. Moreover, we extend our preliminary goal of just anomaly detection to simultaneous anomaly prediction. We approach this very challenging problem by developing a Bayesian Network framework that captures the information about the parameters of the lagged regressors calibrated in the first part of our approach and use this structure to learn local conditional probability distributions.
Unsupervised Learning For Effective User Engagement on Social Media
Nov 11, 2016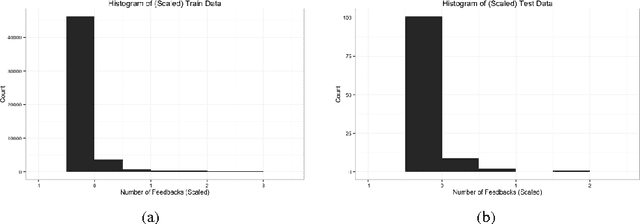

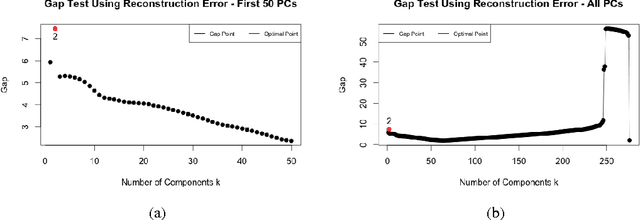
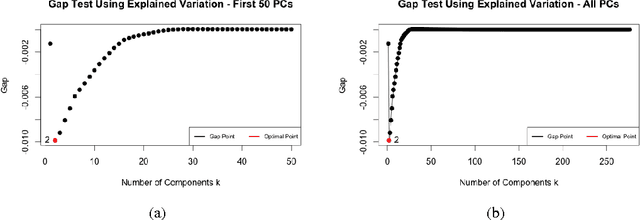
In this paper, we investigate the effectiveness of unsupervised feature learning techniques in predicting user engagement on social media. Specifically, we compare two methods to predict the number of feedbacks (i.e., comments) that a blog post is likely to receive. We compare Principal Component Analysis (PCA) and sparse Autoencoder to a baseline method where the data are only centered and scaled, on each of two models: Linear Regression and Regression Tree. We find that unsupervised learning techniques significantly improve the prediction accuracy on both models. For the Linear Regression model, sparse Autoencoder achieves the best result, with an improvement in the root mean squared error (RMSE) on the test set of 42% over the baseline method. For the Regression Tree model, PCA achieves the best result, with an improvement in RMSE of 15% over the baseline.