 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMind the Gap? A Distributional Comparison of Real and Synthetic Priors for Tabular Foundation Models
May 07, 2026Tabular foundation models are pre-trained on one of three classes of corpus: curated datasets drawn from benchmark repositories, tables harvested at scale from the web, or synthetic tables sampled from a parametric generative prior. Despite the centrality of pre-training data to model performance, little is known about how these corpora relate to one another in distribution, and the impact this has on downstream performance. In this work we take three canonical, archetypal datasets used to train tabular foundation models; the T4 dataset represents web-scraped corpora, the TabFM dataset curated tables from Kaggle, and the TabICL dataset as the only well-used synthetic prior with publicly available parameters. We characterise each corpus using aggregate features over whole tables, columns and correlations, and compare them using discriminator AUCs and k-NN coverage metrics. We find that the TabICL synthetic prior occupies a narrow region of the space of real tables, that this mismatch cannot be closed by optimising prior hyper-parameters across more than 86 thousand configurations, and that curated and web-scraped corpora are broadly interchangeable on a distributional level in feature space. Surprisingly, the distributional gap between synthetic pre-training data and real tables has a clearly detectable effect on performance under neither feature-based proximity measures or TabICL's own internal representations, suggesting that coverage of the real-data distribution is not the primary driver of TabICL's generalisation.
Continual learning and refinement of causal models through dynamic predicate invention
Feb 19, 2026Efficiently navigating complex environments requires agents to internalize the underlying logic of their world, yet standard world modelling methods often struggle with sample inefficiency, lack of transparency, and poor scalability. We propose a framework for constructing symbolic causal world models entirely online by integrating continuous model learning and repair into the agent's decision loop, by leveraging the power of Meta-Interpretive Learning and predicate invention to find semantically meaningful and reusable abstractions, allowing an agent to construct a hierarchy of disentangled, high-quality concepts from its observations. We demonstrate that our lifted inference approach scales to domains with complex relational dynamics, where propositional methods suffer from combinatorial explosion, while achieving sample-efficiency orders of magnitude higher than the established PPO neural-network-based baseline.
LEMON: Local Explanations via Modality-aware OptimizatioN
Feb 02, 2026Multimodal models are ubiquitous, yet existing explainability methods are often single-modal, architecture-dependent, or too computationally expensive to run at scale. We introduce LEMON (Local Explanations via Modality-aware OptimizatioN), a model-agnostic framework for local explanations of multimodal predictions. LEMON fits a single modality-aware surrogate with group-structured sparsity to produce unified explanations that disentangle modality-level contributions and feature-level attributions. The approach treats the predictor as a black box and is computationally efficient, requiring relatively few forward passes while remaining faithful under repeated perturbations. We evaluate LEMON on vision-language question answering and a clinical prediction task with image, text, and tabular inputs, comparing against representative multimodal baselines. Across backbones, LEMON achieves competitive deletion-based faithfulness while reducing black-box evaluations by 35-67 times and runtime by 2-8 times compared to strong multimodal baselines.
A Metric for the Balance of Information in Graph Learning
Jan 31, 2025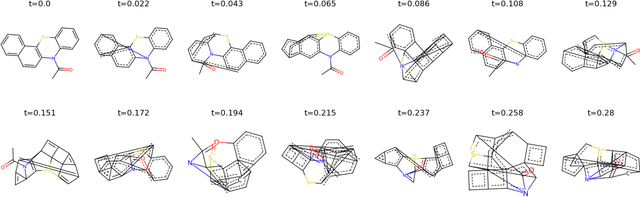
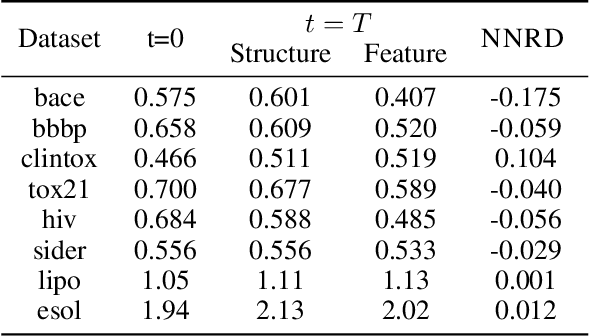

Graph learning on molecules makes use of information from both the molecular structure and the features attached to that structure. Much work has been conducted on biasing either towards structure or features, with the aim that bias bolsters performance. Identifying which information source a dataset favours, and therefore how to approach learning that dataset, is an open issue. Here we propose Noise-Noise Ratio Difference (NNRD), a quantitative metric for whether there is more useful information in structure or features. By employing iterative noising on features and structure independently, leaving the other intact, NNRD measures the degradation of information in each. We employ NNRD over a range of molecular tasks, and show that it corresponds well to a loss of information, with intuitive results that are more expressive than simple performance aggregates. Our future work will focus on expanding data domains, tasks and types, as well as refining our choice of baseline model.
Time-Series Classification for Dynamic Strategies in Multi-Step Forecasting
Feb 13, 2024



Multi-step forecasting (MSF) in time-series, the ability to make predictions multiple time steps into the future, is fundamental to almost all temporal domains. To make such forecasts, one must assume the recursive complexity of the temporal dynamics. Such assumptions are referred to as the forecasting strategy used to train a predictive model. Previous work shows that it is not clear which forecasting strategy is optimal a priori to evaluating on unseen data. Furthermore, current approaches to MSF use a single (fixed) forecasting strategy. In this paper, we characterise the instance-level variance of optimal forecasting strategies and propose Dynamic Strategies (DyStrat) for MSF. We experiment using 10 datasets from different scales, domains, and lengths of multi-step horizons. When using a random-forest-based classifier, DyStrat outperforms the best fixed strategy, which is not knowable a priori, 94% of the time, with an average reduction in mean-squared error of 11%. Our approach typically triples the top-1 accuracy compared to current approaches. Notably, we show DyStrat generalises well for any MSF task.