 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEpistemic Error Decomposition for Multi-step Time Series Forecasting: Rethinking Bias-Variance in Recursive and Direct Strategies
Nov 14, 2025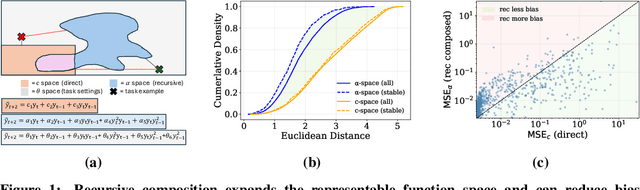
Multi-step forecasting is often described through a simple rule of thumb: recursive strategies are said to have high bias and low variance, while direct strategies are said to have low bias and high variance. We revisit this belief by decomposing the expected multi-step forecast error into three parts: irreducible noise, a structural approximation gap, and an estimation-variance term. For linear predictors we show that the structural gap is identically zero for any dataset. For nonlinear predictors, however, the repeated composition used in recursion can increase model expressivity, making the structural gap depend on both the model and the data. We further show that the estimation variance of the recursive strategy at any horizon can be written as the one-step variance multiplied by a Jacobian-based amplification factor that measures how sensitive the composed predictor is to parameter error. This perspective explains when recursive forecasting may simultaneously have lower bias and higher variance than direct forecasting. Experiments with multilayer perceptrons on the ETTm1 dataset confirm these findings. The results offer practical guidance for choosing between recursive and direct strategies based on model nonlinearity and noise characteristics, rather than relying on traditional bias-variance intuition.
Language Models Do Not Embed Numbers Continuously
Oct 09, 2025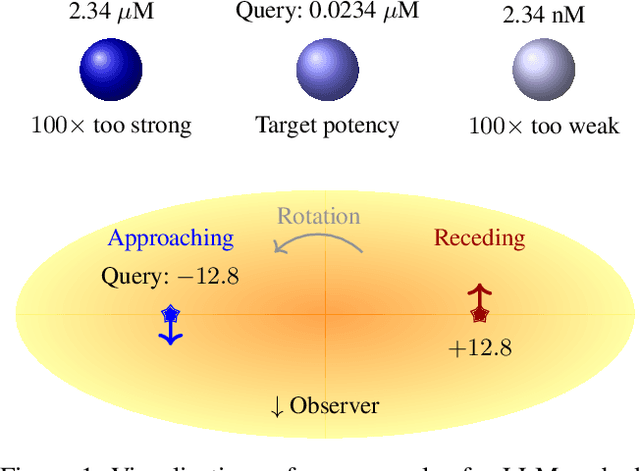

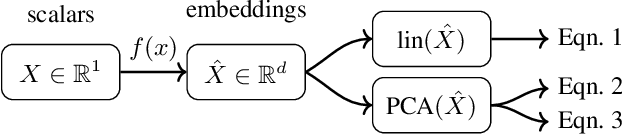
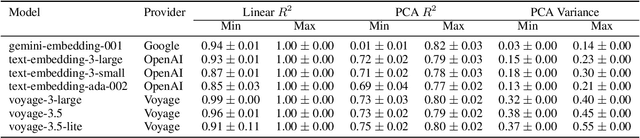
Recent research has extensively studied how large language models manipulate integers in specific arithmetic tasks, and on a more fundamental level, how they represent numeric values. These previous works have found that language model embeddings can be used to reconstruct the original values, however, they do not evaluate whether language models actually model continuous values as continuous. Using expected properties of the embedding space, including linear reconstruction and principal component analysis, we show that language models not only represent numeric spaces as non-continuous but also introduce significant noise. Using models from three major providers (OpenAI, Google Gemini and Voyage AI), we show that while reconstruction is possible with high fidelity ($R^2 \geq 0.95$), principal components only explain a minor share of variation within the embedding space. This indicates that many components within the embedding space are orthogonal to the simple numeric input space. Further, both linear reconstruction and explained variance suffer with increasing decimal precision, despite the ordinal nature of the input space being fundamentally unchanged. The findings of this work therefore have implications for the many areas where embedding models are used, in-particular where high numerical precision, large magnitudes or mixed-sign values are common.
Stratify: Unifying Multi-Step Forecasting Strategies
Dec 29, 2024



A key aspect of temporal domains is the ability to make predictions multiple time steps into the future, a process known as multi-step forecasting (MSF). At the core of this process is selecting a forecasting strategy, however, with no existing frameworks to map out the space of strategies, practitioners are left with ad-hoc methods for strategy selection. In this work, we propose Stratify, a parameterised framework that addresses multi-step forecasting, unifying existing strategies and introducing novel, improved strategies. We evaluate Stratify on 18 benchmark datasets, five function classes, and short to long forecast horizons (10, 20, 40, 80). In over 84% of 1080 experiments, novel strategies in Stratify improved performance compared to all existing ones. Importantly, we find that no single strategy consistently outperforms others in all task settings, highlighting the need for practitioners explore the Stratify space to carefully search and select forecasting strategies based on task-specific requirements. Our results are the most comprehensive benchmarking of known and novel forecasting strategies. We make code available to reproduce our results.
Its All Graph To Me: Foundational Topology Models with Contrastive Learning on Multiple Domains
Nov 07, 2023



Representations and embeddings of graph data have been essential in many domains of research. The principle benefit of learning such representations is that the pre-trained model can be fine-tuned on smaller datasets where data or labels are scarse. Existing models, however, are domain specific; for example a model trained on molecular graphs is fine-tuned on other molecular graphs. This means that in many application cases the choice of pre-trained model can be arbitrary, and novel domains may lack an appropriate pre-trained model. This is of particular issue where data is scarse, precluding traditional supervised methods. In this work we use adversarial contrastive learning to present a \method, a model pre-trained on many graph domains. We train the model only on topologies but include node labels in evaluation. We evaluate the efficacy of its learnt representations on various downstream tasks. Against baseline models pre-trained on single domains, as well as un-trained models and non-transferred models, we show that performance is equal or better using our single model. This includes when node labels are used in evaluation, where performance is consistently superior to single-domain or non-pre-trained models.
Hierarchical GNNs for Large Graph Generation
Jun 20, 2023



Large graphs are present in a variety of domains, including social networks, civil infrastructure, and the physical sciences to name a few. Graph generation is similarly widespread, with applications in drug discovery, network analysis and synthetic datasets among others. While GNN (Graph Neural Network) models have been applied in these domains their high in-memory costs restrict them to small graphs. Conversely less costly rule-based methods struggle to reproduce complex structures. We propose HIGGS (Hierarchical Generation of Graphs) as a model-agnostic framework of producing large graphs with realistic local structures. HIGGS uses GNN models with conditional generation capabilities to sample graphs in hierarchies of resolution. As a result HIGGS has the capacity to extend the scale of generated graphs from a given GNN model by quadratic order. As a demonstration we implement HIGGS using DiGress, a recent graph-diffusion model, including a novel edge-predictive-diffusion variant edge-DiGress. We use this implementation to generate categorically attributed graphs with tens of thousands of nodes. These HIGGS generated graphs are far larger than any previously produced using GNNs. Despite this jump in scale we demonstrate that the graphs produced by HIGGS are, on the local scale, more realistic than those from the rule-based model BTER.
$β^{4}$-IRT: A New $β^{3}$-IRT with Enhanced Discrimination Estimation
Mar 30, 2023
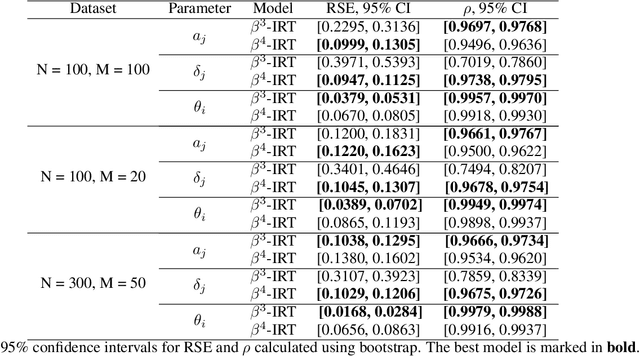


Item response theory aims to estimate respondent's latent skills from their responses in tests composed of items with different levels of difficulty. Several models of item response theory have been proposed for different types of tasks, such as binary or probabilistic responses, response time, multiple responses, among others. In this paper, we propose a new version of $\beta^3$-IRT, called $\beta^{4}$-IRT, which uses the gradient descent method to estimate the model parameters. In $\beta^3$-IRT, abilities and difficulties are bounded, thus we employ link functions in order to turn $\beta^{4}$-IRT into an unconstrained gradient descent process. The original $\beta^3$-IRT had a symmetry problem, meaning that, if an item was initialised with a discrimination value with the wrong sign, e.g. negative when the actual discrimination should be positive, the fitting process could be unable to recover the correct discrimination and difficulty values for the item. In order to tackle this limitation, we modelled the discrimination parameter as the product of two new parameters, one corresponding to the sign and the second associated to the magnitude. We also proposed sensible priors for all parameters. We performed experiments to compare $\beta^{4}$-IRT and $\beta^3$-IRT regarding parameter recovery and our new version outperformed the original $\beta^3$-IRT. Finally, we made $\beta^{4}$-IRT publicly available as a Python package, along with the implementation of $\beta^3$-IRT used in our experiments.