 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrivate, Augmentation-Robust and Task-Agnostic Data Valuation Approach for Data Marketplace
Nov 01, 2024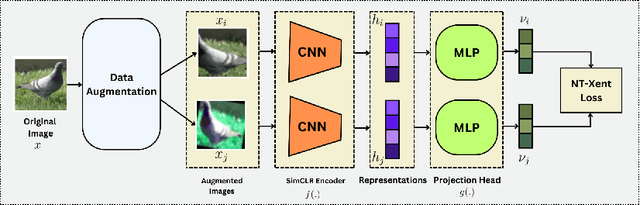
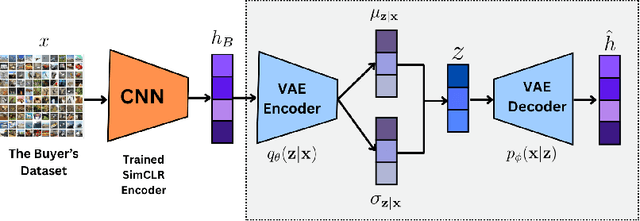
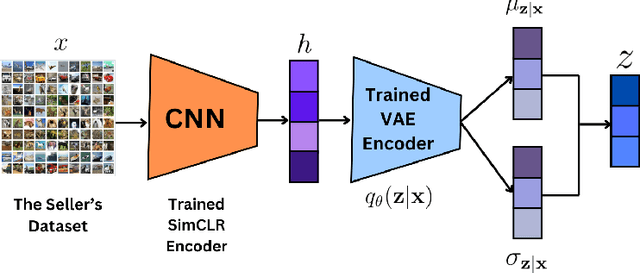
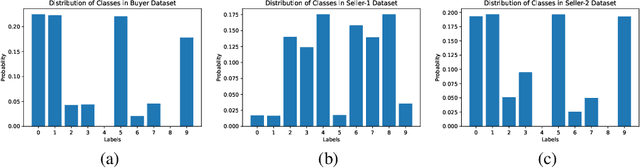
Evaluating datasets in data marketplaces, where the buyer aim to purchase valuable data, is a critical challenge. In this paper, we introduce an innovative task-agnostic data valuation method called PriArTa which is an approach for computing the distance between the distribution of the buyer's existing dataset and the seller's dataset, allowing the buyer to determine how effectively the new data can enhance its dataset. PriArTa is communication-efficient, enabling the buyer to evaluate datasets without needing access to the entire dataset from each seller. Instead, the buyer requests that sellers perform specific preprocessing on their data and then send back the results. Using this information and a scoring metric, the buyer can evaluate the dataset. The preprocessing is designed to allow the buyer to compute the score while preserving the privacy of each seller's dataset, mitigating the risk of information leakage before the purchase. A key feature of PriArTa is its robustness to common data transformations, ensuring consistent value assessment and reducing the risk of purchasing redundant data. The effectiveness of PriArTa is demonstrated through experiments on real-world image datasets, showing its ability to perform privacy-preserving, augmentation-robust data valuation in data marketplaces.
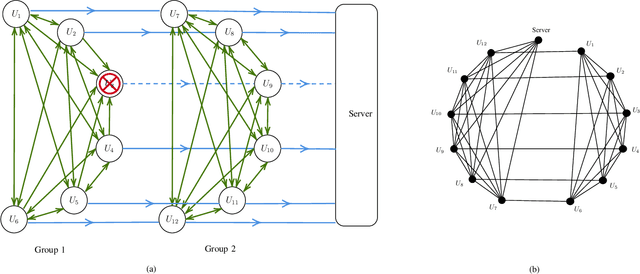
Byzantine-Resistant Secure Aggregation for Federated Learning Based on Coded Computing and Vector Commitment
Feb 20, 2023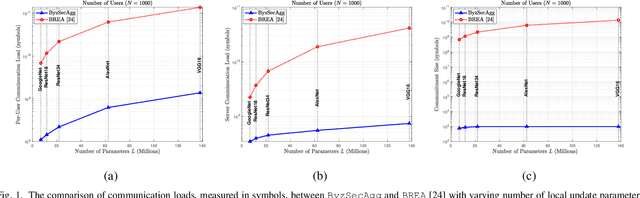
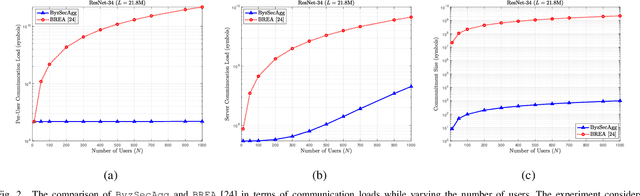

In this paper, we propose an efficient secure aggregation scheme for federated learning that is protected against Byzantine attacks and privacy leakages. Processing individual updates to manage adversarial behavior, while preserving privacy of data against colluding nodes, requires some sort of secure secret sharing. However, communication load for secret sharing of long vectors of updates can be very high. To resolve this issue, in the proposed scheme, local updates are partitioned into smaller sub-vectors and shared using ramp secret sharing. However, this sharing method does not admit bi-linear computations, such as pairwise distance calculations, needed by outlier-detection algorithms. To overcome this issue, each user runs another round of ramp sharing, with different embedding of data in the sharing polynomial. This technique, motivated by ideas from coded computing, enables secure computation of pairwise distance. In addition, to maintain the integrity and privacy of the local update, the proposed scheme also uses a vector commitment method, in which the commitment size remains constant (i.e. does not increase with the length of the local update), while simultaneously allowing verification of the secret sharing process.
SwiftAgg+: Achieving Asymptotically Optimal Communication Load in Secure Aggregation for Federated Learning
Mar 24, 2022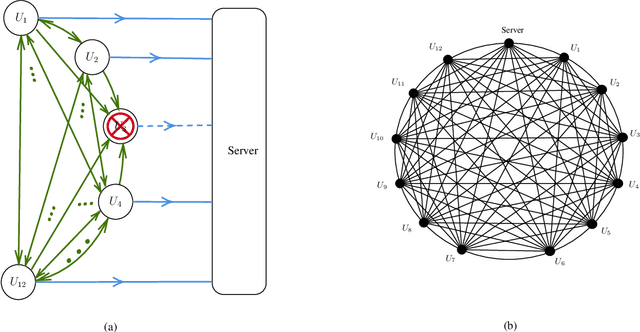
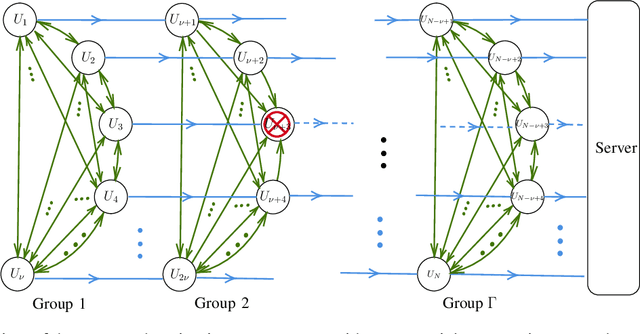
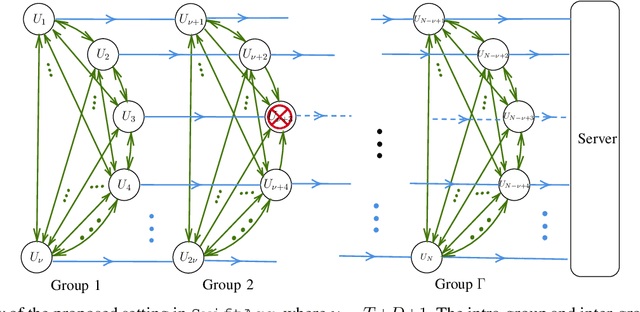
We propose SwiftAgg+, a novel secure aggregation protocol for federated learning systems, where a central server aggregates local models of $N\in\mathbb{N}$ distributed users, each of size $L \in \mathbb{N}$, trained on their local data, in a privacy-preserving manner. SwiftAgg+ can significantly reduce the communication overheads without any compromise on security, and achieve the optimum communication load within a diminishing gap. Specifically, in presence of at most $D$ dropout users, SwiftAgg+ achieves average per-user communication load of $(1+\mathcal{O}(\frac{1}{N}))L$ and the server communication load of $(1+\mathcal{O}(\frac{1}{N}))L$, with a worst-case information-theoretic security guarantee, against any subset of up to $T$ semi-honest users who may also collude with the curious server. The proposed SwiftAgg+ has also a flexibility to reduce the number of active communication links at the cost of increasing the the communication load between the users and the server. In particular, for any $K\in\mathbb{N}$, SwiftAgg+ can achieve the uplink communication load of $(1+\frac{T}{K})L$, and per-user communication load of up to $(1-\frac{1}{N})(1+\frac{T+D}{K})L$, where the number of pair-wise active connections in the network is $\frac{N}{2}(K+T+D+1)$.
SwiftAgg: Communication-Efficient and Dropout-Resistant Secure Aggregation for Federated Learning with Worst-Case Security Guarantees
Feb 08, 2022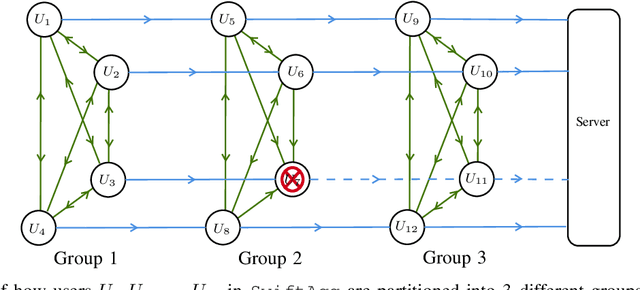

We propose SwiftAgg, a novel secure aggregation protocol for federated learning systems, where a central server aggregates local models of $N$ distributed users, each of size $L$, trained on their local data, in a privacy-preserving manner. Compared with state-of-the-art secure aggregation protocols, SwiftAgg significantly reduces the communication overheads without any compromise on security. Specifically, in presence of at most $D$ dropout users, SwiftAgg achieves a users-to-server communication load of $(T+1)L$ and a users-to-users communication load of up to $(N-1)(T+D+1)L$, with a worst-case information-theoretic security guarantee, against any subset of up to $T$ semi-honest users who may also collude with the curious server. The key idea of SwiftAgg is to partition the users into groups of size $D+T+1$, then in the first phase, secret sharing and aggregation of the individual models are performed within each group, and then in the second phase, model aggregation is performed on $D+T+1$ sequences of users across the groups. If a user in a sequence drops out in the second phase, the rest of the sequence remain silent. This design allows only a subset of users to communicate with each other, and only the users in a single group to directly communicate with the server, eliminating the requirements of 1) all-to-all communication network across users; and 2) all users communicating with the server, for other secure aggregation protocols. This helps to substantially slash the communication costs of the system.
Optimal Communication-Computation Trade-Off in Heterogeneous Gradient Coding
Mar 02, 2021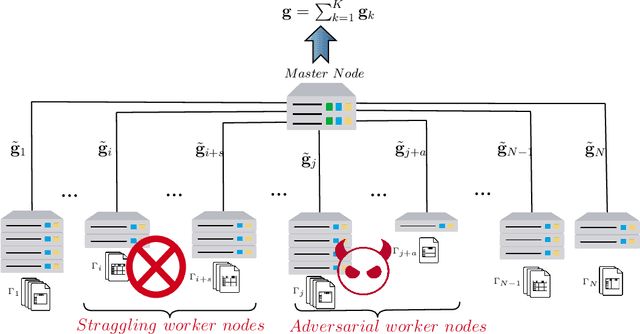
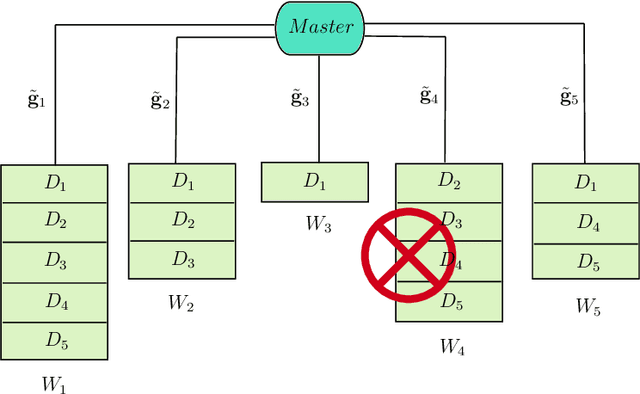
Gradient coding allows a master node to derive the aggregate of the partial gradients, calculated by some worker nodes over the local data sets, with minimum communication cost, and in the presence of stragglers. In this paper, for gradient coding with linear encoding, we characterize the optimum communication cost for heterogeneous distributed systems with \emph{arbitrary} data placement, with $s \in \mathbb{N}$ stragglers and $a \in \mathbb{N}$ adversarial nodes. In particular, we show that the optimum communication cost, normalized by the size of the gradient vectors, is equal to $(r-s-2a)^{-1}$, where $r \in \mathbb{N}$ is the minimum number that a data partition is replicated. In other words, the communication cost is determined by the data partition with the minimum replication, irrespective of the structure of the placement. The proposed achievable scheme also allows us to target the computation of a polynomial function of the aggregated gradient matrix. It also allows us to borrow some ideas from approximation computing and propose an approximate gradient coding scheme for the cases when the repetition in data placement is smaller than what is needed to meet the restriction imposed on communication cost or when the number of stragglers appears to be more than the presumed value in the system design.
Berrut Approximated Coded Computing: Straggler Resistance Beyond Polynomial Computing
Sep 17, 2020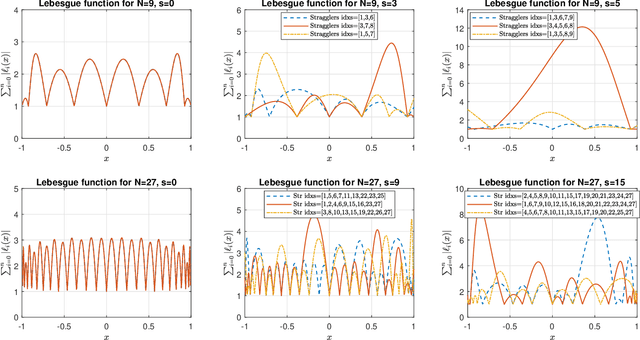
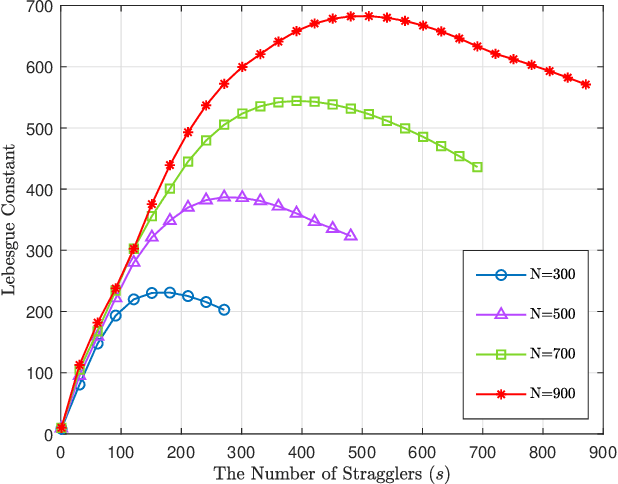
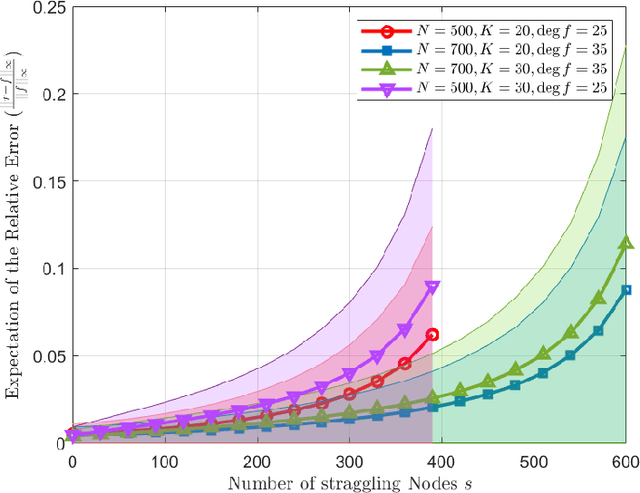
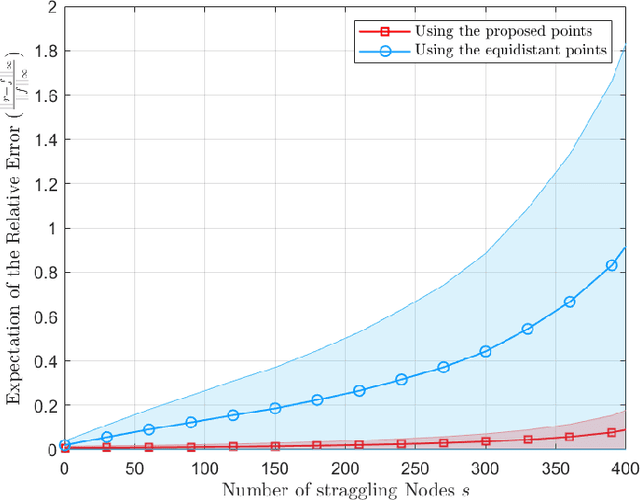
One of the major challenges in using distributed learning to train complicated models with large data sets is to deal with stragglers effect. As a solution, coded computation has been recently proposed to efficiently add redundancy to the computation tasks. In this technique, coding is used across data sets, and computation is done over coded data, such that the results of an arbitrary subset of worker nodes with a certain size are enough to recover the final results. The major challenges with those approaches are (1) they are limited to polynomial function computations, (2) the size of the subset of servers that we need to wait for grows with the multiplication of the size of the data set and the model complexity (the degree of the polynomial), which can be prohibitively large, (3) they are not numerically stable for computation over real numbers. In this paper, we propose Berrut Approximated Coded Computing (BACC), as an alternative approach, which is not limited to polynomial function computation. In addition, the master node can approximately calculate the final results, using the outcomes of any arbitrary subset of available worker nodes. The approximation approach is proven to be numerically stable with low computational complexity. In addition, the accuracy of the approximation is established theoretically and verified by simulation results in different settings such as distributed learning problems. In particular, BACC is used to train a deep neural network on a cluster of servers, which outperforms repetitive computation (repetition coding) in terms of the rate of convergence.