 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDyna-T: Dyna-Q and Upper Confidence Bounds Applied to Trees
Jan 19, 2022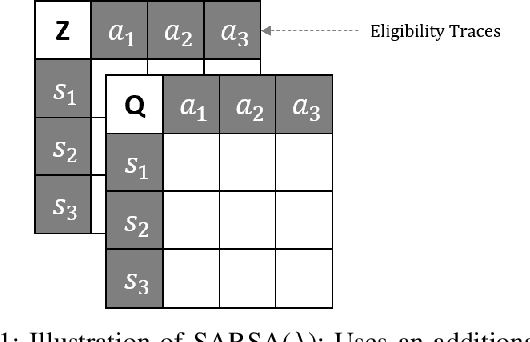
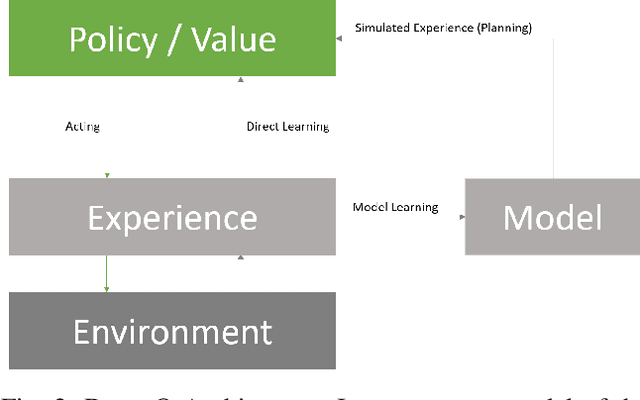
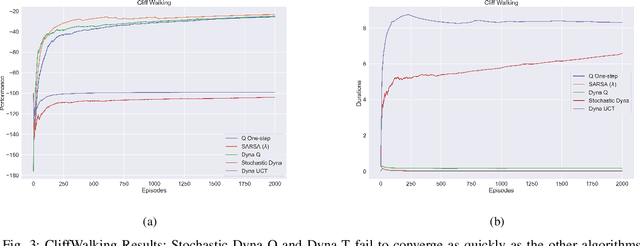
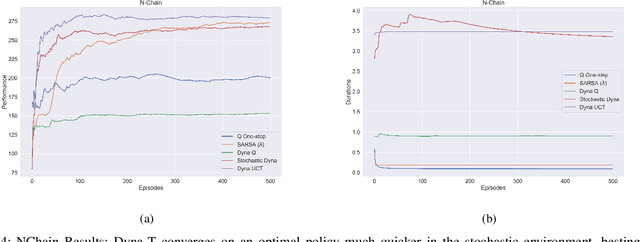
In this work we present a preliminary investigation of a novel algorithm called Dyna-T. In reinforcement learning (RL) a planning agent has its own representation of the environment as a model. To discover an optimal policy to interact with the environment, the agent collects experience in a trial and error fashion. Experience can be used for learning a better model or improve directly the value function and policy. Typically separated, Dyna-Q is an hybrid approach which, at each iteration, exploits the real experience to update the model as well as the value function, while planning its action using simulated data from its model. However, the planning process is computationally expensive and strongly depends on the dimensionality of the state-action space. We propose to build a Upper Confidence Tree (UCT) on the simulated experience and search for the best action to be selected during the on-line learning process. We prove the effectiveness of our proposed method on a set of preliminary tests on three testbed environments from Open AI. In contrast to Dyna-Q, Dyna-T outperforms state-of-the-art RL agents in the stochastic environments by choosing a more robust action selection strategy.
Direct Mutation and Crossover in Genetic Algorithms Applied to Reinforcement Learning Tasks
Jan 19, 2022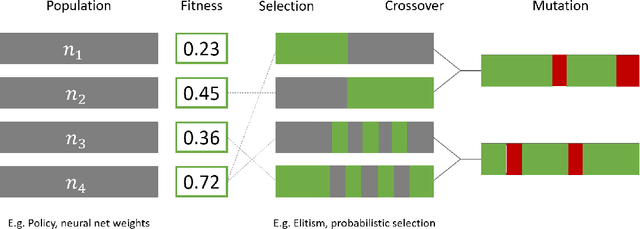
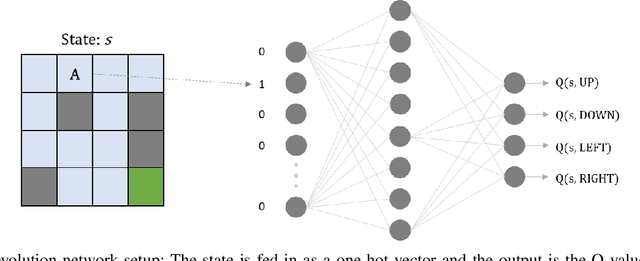
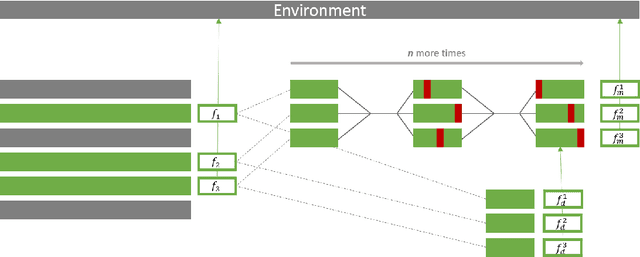
Neuroevolution has recently been shown to be quite competitive in reinforcement learning (RL) settings, and is able to alleviate some of the drawbacks of gradient-based approaches. This paper will focus on applying neuroevolution using a simple genetic algorithm (GA) to find the weights of a neural network that produce optimally behaving agents. In addition, we present two novel modifications that improve the data efficiency and speed of convergence when compared to the initial implementation. The modifications are evaluated on the FrozenLake environment provided by OpenAI gym and prove to be significantly better than the baseline approach.