 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccelerating Large Scale Knowledge Distillation via Dynamic Importance Sampling
Dec 03, 2018
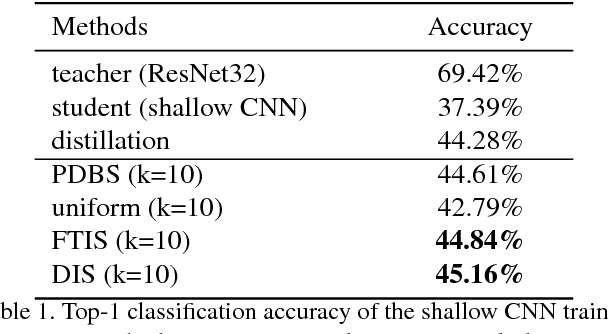
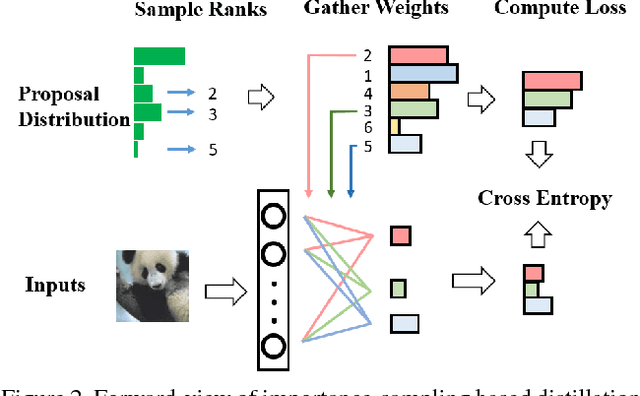

Knowledge distillation is an effective technique that transfers knowledge from a large teacher model to a shallow student. However, just like massive classification, large scale knowledge distillation also imposes heavy computational costs on training models of deep neural networks, as the softmax activations at the last layer involve computing probabilities over numerous classes. In this work, we apply the idea of importance sampling which is often used in Neural Machine Translation on large scale knowledge distillation. We present a method called dynamic importance sampling, where ranked classes are sampled from a dynamic distribution derived from the interaction between the teacher and student in full distillation. We highlight the utility of our proposal prior which helps the student capture the main information in the loss function. Our approach manages to reduce the computational cost at training time while maintaining the competitive performance on CIFAR-100 and Market-1501 person re-identification datasets.