 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamically Weighted Federated k-Means
Oct 23, 2023Federated clustering is an important part of the field of federated machine learning, that allows multiple data sources to collaboratively cluster their data while keeping it decentralized and preserving privacy. In this paper, we introduce a novel federated clustering algorithm, named Dynamically Weighted Federated k-means (DWF k-means), to address the challenges posed by distributed data sources and heterogeneous data. Our proposed algorithm combines the benefits of traditional clustering techniques with the privacy and scalability advantages of federated learning. It enables multiple data owners to collaboratively cluster their local data while exchanging minimal information with a central coordinator. The algorithm optimizes the clustering process by adaptively aggregating cluster assignments and centroids from each data source, thereby learning a global clustering solution that reflects the collective knowledge of the entire federated network. We conduct experiments on multiple datasets and data distribution settings to evaluate the performance of our algorithm in terms of clustering score, accuracy, and v-measure. The results demonstrate that our approach can match the performance of the centralized classical k-means baseline, and outperform existing federated clustering methods in realistic scenarios.
Fed-DART and FACT: A solution for Federated Learning in a production environment
May 23, 2022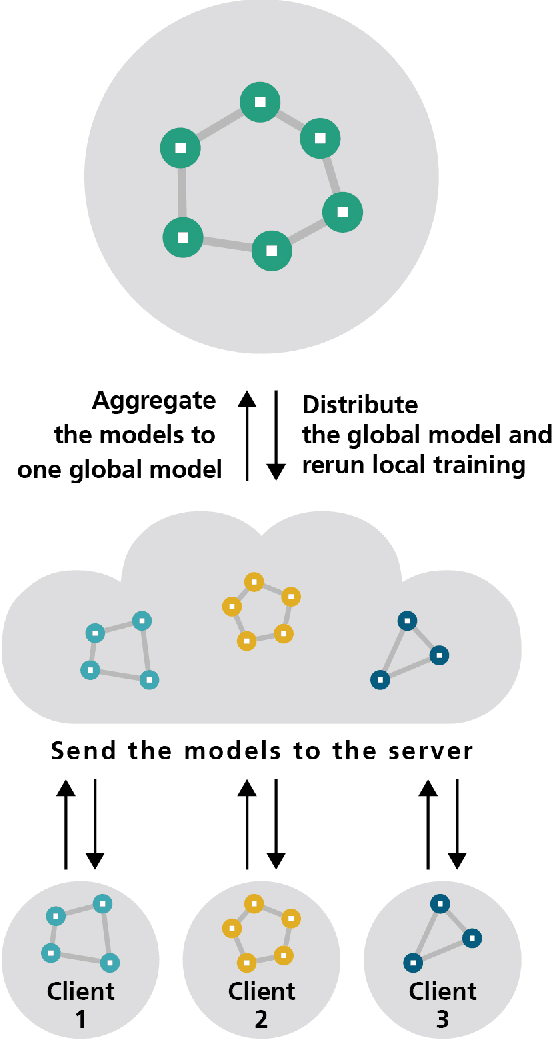
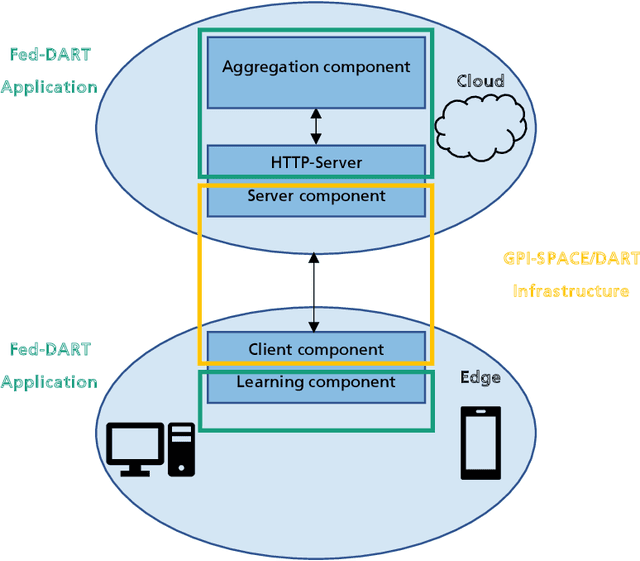
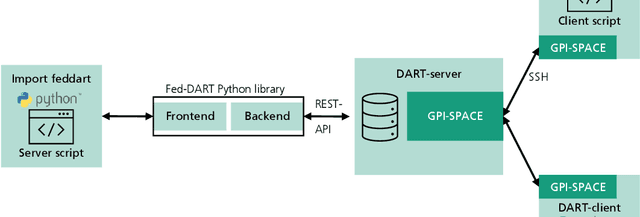
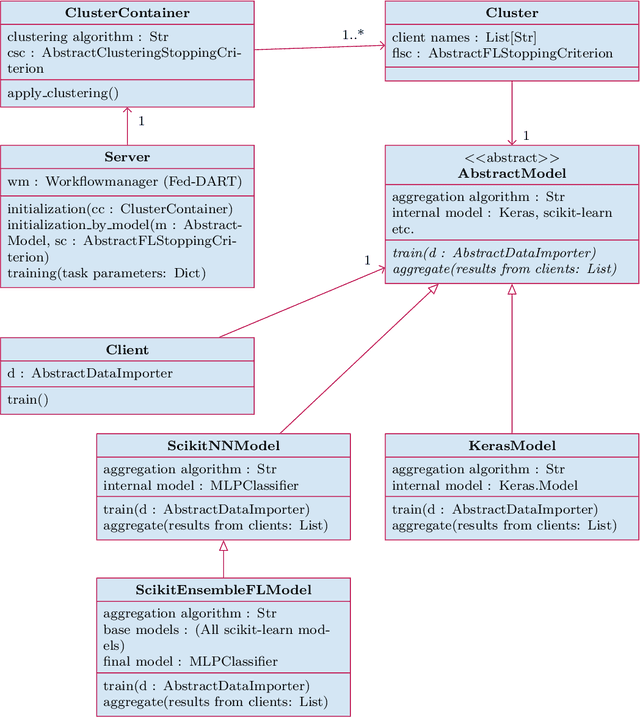
Federated Learning as a decentralized artificial intelligence (AI) solution solves a variety of problems in industrial applications. It enables a continuously self-improving AI, which can be deployed everywhere at the edge. However, bringing AI to production for generating a real business impact is a challenging task. Especially in the case of Federated Learning, expertise and resources from multiple domains are required to realize its full potential. Having this in mind we have developed an innovative Federated Learning framework FACT based on Fed-DART, enabling an easy and scalable deployment, helping the user to fully leverage the potential of their private and decentralized data.