 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantic Example Guided Image-to-Image Translation
Oct 04, 2019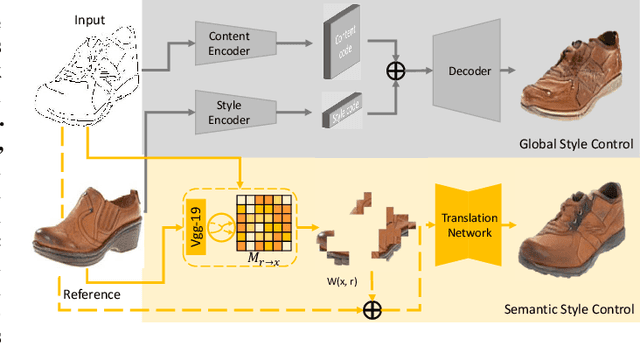


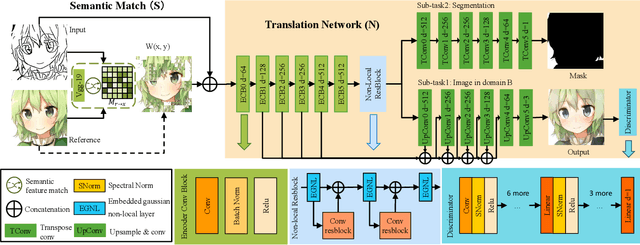
Many image-to-image (I2I) translation problems are in nature of high diversity that a single input may have various counterparts. Prior works proposed the multi-modal network that can build a many-to-many mapping between two visual domains. However, most of them are guided by sampled noises. Some others encode the reference images into a latent vector, by which the semantic information of the reference image will be washed away. In this work, we aim to provide a solution to control the output based on references semantically. Given a reference image and an input in another domain, a semantic matching is first performed between the two visual contents and generates the auxiliary image, which is explicitly encouraged to preserve semantic characteristics of the reference. A deep network then is used for I2I translation and the final outputs are expected to be semantically similar to both the input and the reference; however, no such paired data can satisfy that dual-similarity in a supervised fashion, so we build up a self-supervised framework to serve the training purpose. We improve the quality and diversity of the outputs by employing non-local blocks and a multi-task architecture. We assess the proposed method through extensive qualitative and quantitative evaluations and also presented comparisons with several state-of-art models.