 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDelta-ICM: Entropy Modeling with Delta Function for Learned Image Compression
Oct 10, 2024


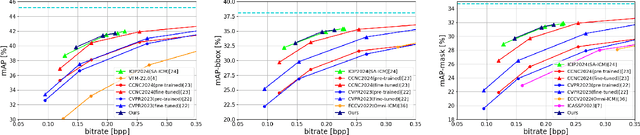
Image Coding for Machines (ICM) is becoming more important as research in computer vision progresses. ICM is a vital research field that pursues the use of images for image recognition models, facilitating efficient image transmission and storage. The demand for recognition models is growing rapidly among the general public, and their performance continues to improve. To meet these needs, exchanging image data between consumer devices and cloud AI using ICM technology could be one possible solution. In ICM, various image compression methods have adopted Learned Image Compression (LIC). LIC includes an entropy model for estimating the bitrate of latent features, and the design of this model significantly affects its performance. Typically, LIC methods assume that the distribution of latent features follows a normal distribution. This assumption is effective for compressing images intended for human vision. However, employing an entropy model based on normal distribution is inefficient in ICM due to the limitation of image parts that require precise decoding. To address this, we propose Delta-ICM, which uses a probability distribution based on a delta function. Assuming the delta distribution as a distribution of latent features reduces the entropy of image portions unnecessary for machines. We compress the remaining portions using an entropy model based on normal distribution, similar to existing methods. Delta-ICM selects between the entropy model based on the delta distribution and the one based on the normal distribution for each latent feature. Our method outperforms existing ICM methods in image compression performance aimed at machines.
Refining Coded Image in Human Vision Layer Using CNN-Based Post-Processing
May 20, 2024Scalable image coding for both humans and machines is a technique that has gained a lot of attention recently. This technology enables the hierarchical decoding of images for human vision and image recognition models. It is a highly effective method when images need to serve both purposes. However, no research has yet incorporated the post-processing commonly used in popular image compression schemes into scalable image coding method for humans and machines. In this paper, we propose a method to enhance the quality of decoded images for humans by integrating post-processing into scalable coding scheme. Experimental results show that the post-processing improves compression performance. Furthermore, the effectiveness of the proposed method is validated through comparisons with traditional methods.
Image Coding for Machines with Edge Information Learning Using Segment Anything
Mar 07, 2024Image Coding for Machines (ICM) is an image compression technique for image recognition. This technique is essential due to the growing demand for image recognition AI. In this paper, we propose a method for ICM that focuses on encoding and decoding only the edge information of object parts in an image, which we call SA-ICM. This is an Learned Image Compression (LIC) model trained using edge information created by Segment Anything. Our method can be used for image recognition models with various tasks. SA-ICM is also robust to changes in input data, making it effective for a variety of use cases. Additionally, our method provides benefits from a privacy point of view, as it removes human facial information on the encoder's side, thus protecting one's privacy. Furthermore, this LIC model training method can be used to train Neural Representations for Videos (NeRV), which is a video compression model. By training NeRV using edge information created by Segment Anything, it is possible to create a NeRV that is effective for image recognition (SA-NeRV). Experimental results confirm the advantages of SA-ICM, presenting the best performance in image compression for image recognition. We also show that SA-NeRV is superior to ordinary NeRV in video compression for machines.
Image Coding for Machines with Object Region Learning
Aug 27, 2023Compression technology is essential for efficient image transmission and storage. With the rapid advances in deep learning, images are beginning to be used for image recognition as well as for human vision. For this reason, research has been conducted on image coding for image recognition, and this field is called Image Coding for Machines (ICM). There are two main approaches in ICM: the ROI-based approach and the task-loss-based approach. The former approach has the problem of requiring an ROI-map as input in addition to the input image. The latter approach has the problems of difficulty in learning the task-loss, and lack of robustness because the specific image recognition model is used to compute the loss function. To solve these problems, we propose an image compression model that learns object regions. Our model does not require additional information as input, such as an ROI-map, and does not use task-loss. Therefore, it is possible to compress images for various image recognition models. In the experiments, we demonstrate the versatility of the proposed method by using three different image recognition models and three different datasets. In addition, we verify the effectiveness of our model by comparing it with previous methods.
VVC Extension Scheme for Object Detection Using Contrast Reduction
May 30, 2023In recent years, video analysis using Artificial Intelligence (AI) has been widely used, due to the remarkable development of image recognition technology using deep learning. In 2019, the Moving Picture Experts Group (MPEG) has started standardization of Video Coding for Machines (VCM) as a video coding technology for image recognition. In the framework of VCM, both higher image recognition accuracy and video compression performance are required. In this paper, we propose an extention scheme of video coding for object detection using Versatile Video Coding (VVC). Unlike video for human vision, video used for object detection does not require a large image size or high contrast. Since downsampling of the image can reduce the amount of information to be transmitted. Due to the decrease in image contrast, entropy of the image becomes smaller. Therefore, in our proposed scheme, the original image is reduced in size and contrast, then coded with VVC encoder to achieve high compression performance. Then, the output image from the VVC decoder is restored to its original image size using the bicubic method. Experimental results show that the proposed video coding scheme achieves better coding performance than regular VVC in terms of object detection accuracy.
Accuracy Improvement of Object Detection in VVC Coded Video Using YOLO-v7 Features
Apr 03, 2023With advances in image recognition technology based on deep learning, automatic video analysis by Artificial Intelligence is becoming more widespread. As the amount of video used for image recognition increases, efficient compression methods for such video data are necessary. In general, when the image quality deteriorates due to image encoding, the image recognition accuracy also falls. Therefore, in this paper, we propose a neural-network-based approach to improve image recognition accuracy, especially the object detection accuracy by applying post-processing to the encoded video. Versatile Video Coding (VVC) will be used for the video compression method, since it is the latest video coding method with the best encoding performance. The neural network is trained using the features of YOLO-v7, the latest object detection model. By using VVC as the video coding method and YOLO-v7 as the detection model, high object detection accuracy is achieved even at low bit rates. Experimental results show that the combination of the proposed method and VVC achieves better coding performance than regular VVC in object detection accuracy.