 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLiteSeg: A Novel Lightweight ConvNet for Semantic Segmentation
Dec 13, 2019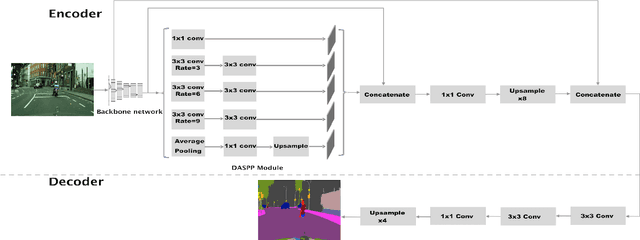



Semantic image segmentation plays a pivotal role in many vision applications including autonomous driving and medical image analysis. Most of the former approaches move towards enhancing the performance in terms of accuracy with a little awareness of computational efficiency. In this paper, we introduce LiteSeg, a lightweight architecture for semantic image segmentation. In this work, we explore a new deeper version of Atrous Spatial Pyramid Pooling module (ASPP) and apply short and long residual connections, and depthwise separable convolution, resulting in a faster and efficient model. LiteSeg architecture is introduced and tested with multiple backbone networks as Darknet19, MobileNet, and ShuffleNet to provide multiple trade-offs between accuracy and computational cost. The proposed model LiteSeg, with MobileNetV2 as a backbone network, achieves an accuracy of 67.81% mean intersection over union at 161 frames per second with $640 \times 360$ resolution on the Cityscapes dataset.