 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCovRL: Fuzzing JavaScript Engines with Coverage-Guided Reinforcement Learning for LLM-based Mutation
Feb 19, 2024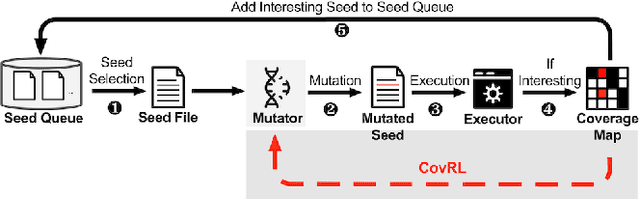
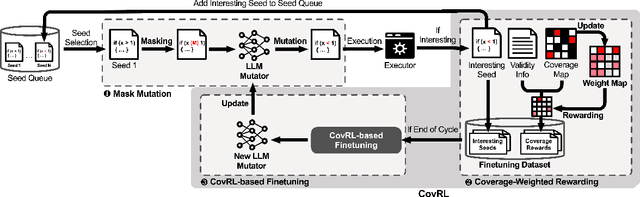
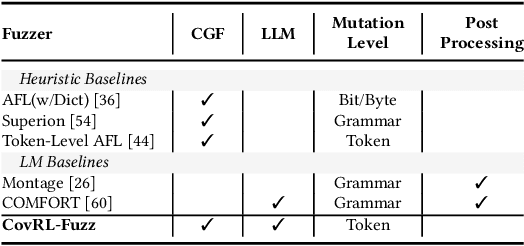
Fuzzing is an effective bug-finding technique but it struggles with complex systems like JavaScript engines that demand precise grammatical input. Recently, researchers have adopted language models for context-aware mutation in fuzzing to address this problem. However, existing techniques are limited in utilizing coverage guidance for fuzzing, which is rather performed in a black-box manner. This paper presents a novel technique called CovRL (Coverage-guided Reinforcement Learning) that combines Large Language Models (LLMs) with reinforcement learning from coverage feedback. Our fuzzer, CovRL-Fuzz, integrates coverage feedback directly into the LLM by leveraging the Term Frequency-Inverse Document Frequency (TF-IDF) method to construct a weighted coverage map. This map is key in calculating the fuzzing reward, which is then applied to the LLM-based mutator through reinforcement learning. CovRL-Fuzz, through this approach, enables the generation of test cases that are more likely to discover new coverage areas, thus improving vulnerability detection while minimizing syntax and semantic errors, all without needing extra post-processing. Our evaluation results indicate that CovRL-Fuzz outperforms the state-of-the-art fuzzers in terms of code coverage and bug-finding capabilities: CovRL-Fuzz identified 48 real-world security-related bugs in the latest JavaScript engines, including 39 previously unknown vulnerabilities and 11 CVEs.
Amplifying Training Data Exposure through Fine-Tuning with Pseudo-Labeled Memberships
Feb 19, 2024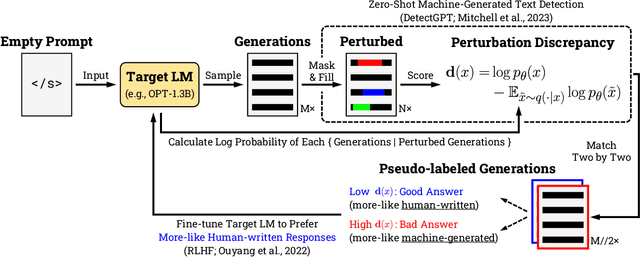
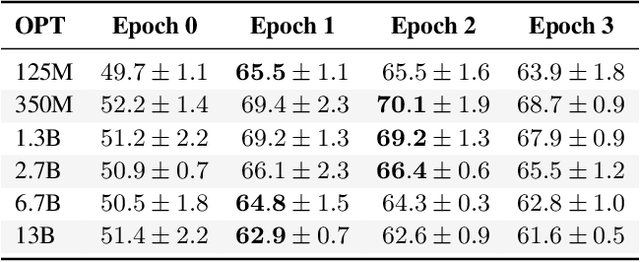
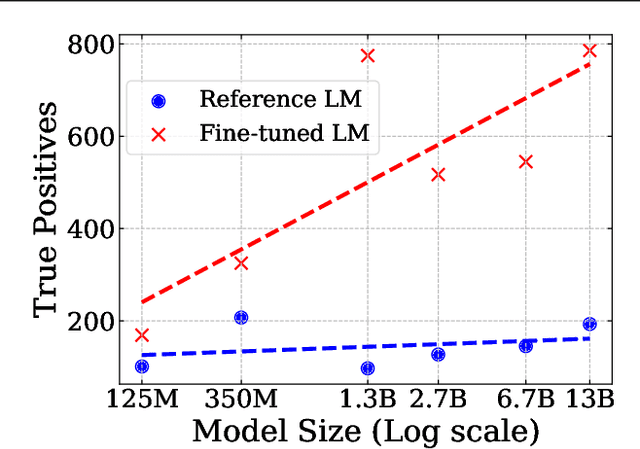

Neural language models (LMs) are vulnerable to training data extraction attacks due to data memorization. This paper introduces a novel attack scenario wherein an attacker adversarially fine-tunes pre-trained LMs to amplify the exposure of the original training data. This strategy differs from prior studies by aiming to intensify the LM's retention of its pre-training dataset. To achieve this, the attacker needs to collect generated texts that are closely aligned with the pre-training data. However, without knowledge of the actual dataset, quantifying the amount of pre-training data within generated texts is challenging. To address this, we propose the use of pseudo-labels for these generated texts, leveraging membership approximations indicated by machine-generated probabilities from the target LM. We subsequently fine-tune the LM to favor generations with higher likelihoods of originating from the pre-training data, based on their membership probabilities. Our empirical findings indicate a remarkable outcome: LMs with over 1B parameters exhibit a four to eight-fold increase in training data exposure. We discuss potential mitigations and suggest future research directions.
Adversarial Feature Alignment: Balancing Robustness and Accuracy in Deep Learning via Adversarial Training
Feb 19, 2024Deep learning models continue to advance in accuracy, yet they remain vulnerable to adversarial attacks, which often lead to the misclassification of adversarial examples. Adversarial training is used to mitigate this problem by increasing robustness against these attacks. However, this approach typically reduces a model's standard accuracy on clean, non-adversarial samples. The necessity for deep learning models to balance both robustness and accuracy for security is obvious, but achieving this balance remains challenging, and the underlying reasons are yet to be clarified. This paper proposes a novel adversarial training method called Adversarial Feature Alignment (AFA), to address these problems. Our research unveils an intriguing insight: misalignment within the feature space often leads to misclassification, regardless of whether the samples are benign or adversarial. AFA mitigates this risk by employing a novel optimization algorithm based on contrastive learning to alleviate potential feature misalignment. Through our evaluations, we demonstrate the superior performance of AFA. The baseline AFA delivers higher robust accuracy than previous adversarial contrastive learning methods while minimizing the drop in clean accuracy to 1.86% and 8.91% on CIFAR10 and CIFAR100, respectively, in comparison to cross-entropy. We also show that joint optimization of AFA and TRADES, accompanied by data augmentation using a recent diffusion model, achieves state-of-the-art accuracy and robustness.