 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMi:dm 2.0 Korea-centric Bilingual Language Models
Jan 14, 2026We introduce Mi:dm 2.0, a bilingual large language model (LLM) specifically engineered to advance Korea-centric AI. This model goes beyond Korean text processing by integrating the values, reasoning patterns, and commonsense knowledge inherent to Korean society, enabling nuanced understanding of cultural contexts, emotional subtleties, and real-world scenarios to generate reliable and culturally appropriate responses. To address limitations of existing LLMs, often caused by insufficient or low-quality Korean data and lack of cultural alignment, Mi:dm 2.0 emphasizes robust data quality through a comprehensive pipeline that includes proprietary data cleansing, high-quality synthetic data generation, strategic data mixing with curriculum learning, and a custom Korean-optimized tokenizer to improve efficiency and coverage. To realize this vision, we offer two complementary configurations: Mi:dm 2.0 Base (11.5B parameters), built with a depth-up scaling strategy for general-purpose use, and Mi:dm 2.0 Mini (2.3B parameters), optimized for resource-constrained environments and specialized tasks. Mi:dm 2.0 achieves state-of-the-art performance on Korean-specific benchmarks, with top-tier zero-shot results on KMMLU and strong internal evaluation results across language, humanities, and social science tasks. The Mi:dm 2.0 lineup is released under the MIT license to support extensive research and commercial use. By offering accessible and high-performance Korea-centric LLMs, KT aims to accelerate AI adoption across Korean industries, public services, and education, strengthen the Korean AI developer community, and lay the groundwork for the broader vision of K-intelligence. Our models are available at https://huggingface.co/K-intelligence. For technical inquiries, please contact midm-llm@kt.com.
Amplifying Training Data Exposure through Fine-Tuning with Pseudo-Labeled Memberships
Feb 19, 2024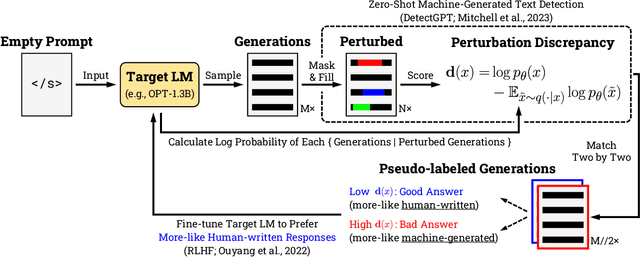
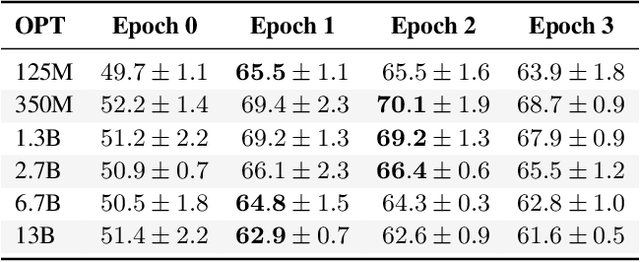
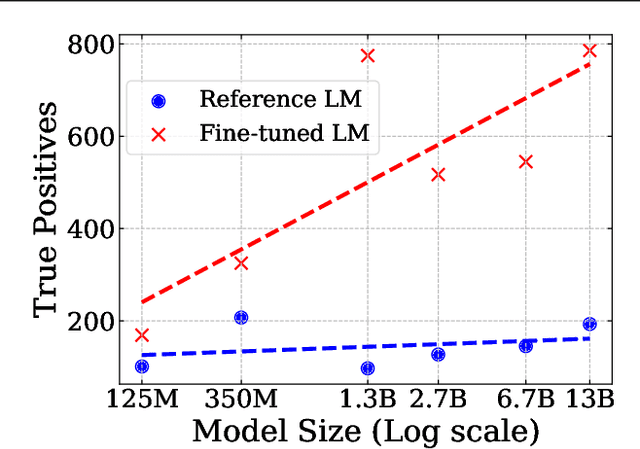

Neural language models (LMs) are vulnerable to training data extraction attacks due to data memorization. This paper introduces a novel attack scenario wherein an attacker adversarially fine-tunes pre-trained LMs to amplify the exposure of the original training data. This strategy differs from prior studies by aiming to intensify the LM's retention of its pre-training dataset. To achieve this, the attacker needs to collect generated texts that are closely aligned with the pre-training data. However, without knowledge of the actual dataset, quantifying the amount of pre-training data within generated texts is challenging. To address this, we propose the use of pseudo-labels for these generated texts, leveraging membership approximations indicated by machine-generated probabilities from the target LM. We subsequently fine-tune the LM to favor generations with higher likelihoods of originating from the pre-training data, based on their membership probabilities. Our empirical findings indicate a remarkable outcome: LMs with over 1B parameters exhibit a four to eight-fold increase in training data exposure. We discuss potential mitigations and suggest future research directions.
Adversarial Feature Alignment: Balancing Robustness and Accuracy in Deep Learning via Adversarial Training
Feb 19, 2024Deep learning models continue to advance in accuracy, yet they remain vulnerable to adversarial attacks, which often lead to the misclassification of adversarial examples. Adversarial training is used to mitigate this problem by increasing robustness against these attacks. However, this approach typically reduces a model's standard accuracy on clean, non-adversarial samples. The necessity for deep learning models to balance both robustness and accuracy for security is obvious, but achieving this balance remains challenging, and the underlying reasons are yet to be clarified. This paper proposes a novel adversarial training method called Adversarial Feature Alignment (AFA), to address these problems. Our research unveils an intriguing insight: misalignment within the feature space often leads to misclassification, regardless of whether the samples are benign or adversarial. AFA mitigates this risk by employing a novel optimization algorithm based on contrastive learning to alleviate potential feature misalignment. Through our evaluations, we demonstrate the superior performance of AFA. The baseline AFA delivers higher robust accuracy than previous adversarial contrastive learning methods while minimizing the drop in clean accuracy to 1.86% and 8.91% on CIFAR10 and CIFAR100, respectively, in comparison to cross-entropy. We also show that joint optimization of AFA and TRADES, accompanied by data augmentation using a recent diffusion model, achieves state-of-the-art accuracy and robustness.