 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTractable Multinomial Logit Contextual Bandits with Non-Linear Utilities
Jan 11, 2026We study the multinomial logit (MNL) contextual bandit problem for sequential assortment selection. Although most existing research assumes utility functions to be linear in item features, this linearity assumption restricts the modeling of intricate interactions between items and user preferences. A recent work (Zhang & Luo, 2024) has investigated general utility function classes, yet its method faces fundamental trade-offs between computational tractability and statistical efficiency. To address this limitation, we propose a computationally efficient algorithm for MNL contextual bandits leveraging the upper confidence bound principle, specifically designed for non-linear parametric utility functions, including those modeled by neural networks. Under a realizability assumption and a mild geometric condition on the utility function class, our algorithm achieves a regret bound of $\tilde{O}(\sqrt{T})$, where $T$ denotes the total number of rounds. Our result establishes that sharp $\tilde{O}(\sqrt{T})$-regret is attainable even with neural network-based utilities, without relying on strong assumptions such as neural tangent kernel approximations. To the best of our knowledge, our proposed method is the first computationally tractable algorithm for MNL contextual bandits with non-linear utilities that provably attains $\tilde{O}(\sqrt{T})$ regret. Comprehensive numerical experiments validate the effectiveness of our approach, showing robust performance not only in realizable settings but also in scenarios with model misspecification.
Lasso Bandit with Compatibility Condition on Optimal Arm
Jun 02, 2024We consider a stochastic sparse linear bandit problem where only a sparse subset of context features affects the expected reward function, i.e., the unknown reward parameter has sparse structure. In the existing Lasso bandit literature, the compatibility conditions together with additional diversity conditions on the context features are imposed to achieve regret bounds that only depend logarithmically on the ambient dimension $d$. In this paper, we demonstrate that even without the additional diversity assumptions, the compatibility condition only on the optimal arm is sufficient to derive a regret bound that depends logarithmically on $d$, and our assumption is strictly weaker than those used in the lasso bandit literature under the single parameter setting. We propose an algorithm that adapts the forced-sampling technique and prove that the proposed algorithm achieves $O(\text{poly}\log dT)$ regret under the margin condition. To our knowledge, the proposed algorithm requires the weakest assumptions among Lasso bandit algorithms under a single parameter setting that achieve $O(\text{poly}\log dT)$ regret. Through the numerical experiments, we confirm the superior performance of our proposed algorithm.
Combinatorial Neural Bandits
May 31, 2023We consider a contextual combinatorial bandit problem where in each round a learning agent selects a subset of arms and receives feedback on the selected arms according to their scores. The score of an arm is an unknown function of the arm's feature. Approximating this unknown score function with deep neural networks, we propose algorithms: Combinatorial Neural UCB ($\texttt{CN-UCB}$) and Combinatorial Neural Thompson Sampling ($\texttt{CN-TS}$). We prove that $\texttt{CN-UCB}$ achieves $\tilde{\mathcal{O}}(\tilde{d} \sqrt{T})$ or $\tilde{\mathcal{O}}(\sqrt{\tilde{d} T K})$ regret, where $\tilde{d}$ is the effective dimension of a neural tangent kernel matrix, $K$ is the size of a subset of arms, and $T$ is the time horizon. For $\texttt{CN-TS}$, we adapt an optimistic sampling technique to ensure the optimism of the sampled combinatorial action, achieving a worst-case (frequentist) regret of $\tilde{\mathcal{O}}(\tilde{d} \sqrt{TK})$. To the best of our knowledge, these are the first combinatorial neural bandit algorithms with regret performance guarantees. In particular, $\texttt{CN-TS}$ is the first Thompson sampling algorithm with the worst-case regret guarantees for the general contextual combinatorial bandit problem. The numerical experiments demonstrate the superior performances of our proposed algorithms.
Model-Based Reinforcement Learning with Multinomial Logistic Function Approximation
Dec 27, 2022

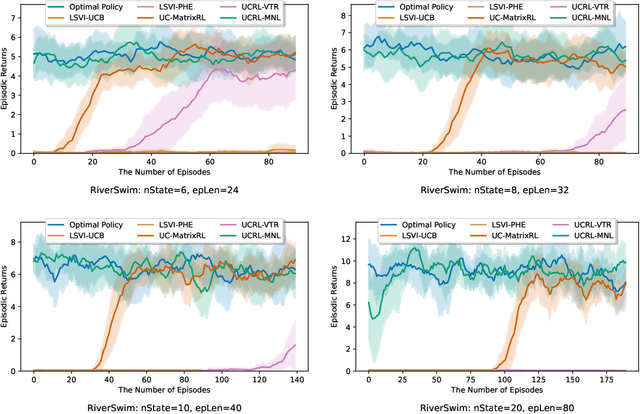

We study model-based reinforcement learning (RL) for episodic Markov decision processes (MDP) whose transition probability is parametrized by an unknown transition core with features of state and action. Despite much recent progress in analyzing algorithms in the linear MDP setting, the understanding of more general transition models is very restrictive. In this paper, we establish a provably efficient RL algorithm for the MDP whose state transition is given by a multinomial logistic model. To balance the exploration-exploitation trade-off, we propose an upper confidence bound-based algorithm. We show that our proposed algorithm achieves $\tilde{\mathcal{O}}(d \sqrt{H^3 T})$ regret bound where $d$ is the dimension of the transition core, $H$ is the horizon, and $T$ is the total number of steps. To the best of our knowledge, this is the first model-based RL algorithm with multinomial logistic function approximation with provable guarantees. We also comprehensively evaluate our proposed algorithm numerically and show that it consistently outperforms the existing methods, hence achieving both provable efficiency and practical superior performance.