 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCommitBERT: Commit Message Generation Using Pre-Trained Programming Language Model
May 29, 2021

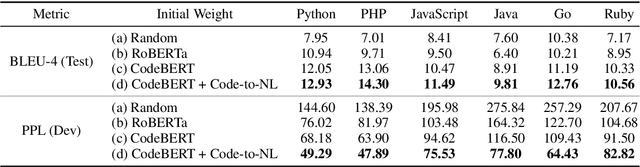
Commit message is a document that summarizes source code changes in natural language. A good commit message clearly shows the source code changes, so this enhances collaboration between developers. Therefore, our work is to develop a model that automatically writes the commit message. To this end, we release 345K datasets consisting of code modification and commit messages in six programming languages (Python, PHP, Go, Java, JavaScript, and Ruby). Similar to the neural machine translation (NMT) model, using our dataset, we feed the code modification to the encoder input and the commit message to the decoder input and measure the result of the generated commit message with BLEU-4. Also, we propose the following two training methods to improve the result of generating the commit message: (1) A method of preprocessing the input to feed the code modification to the encoder input. (2) A method that uses an initial weight suitable for the code domain to reduce the gap in contextual representation between programming language (PL) and natural language (NL). Training code, dataset, and pre-trained weights are available at https://github.com/graykode/commit-autosuggestions
Large Product Key Memory for Pretrained Language Models
Oct 08, 2020
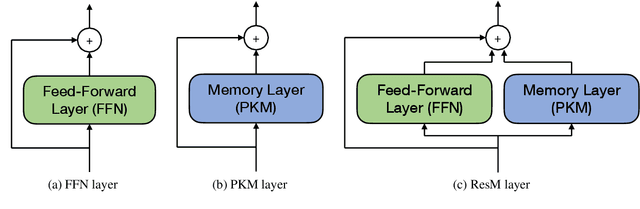
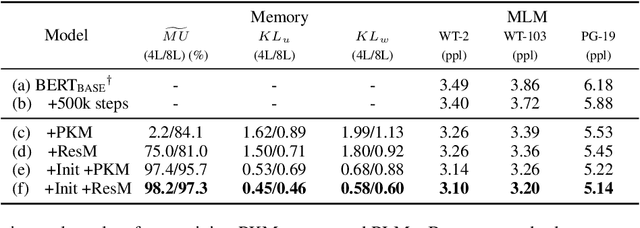
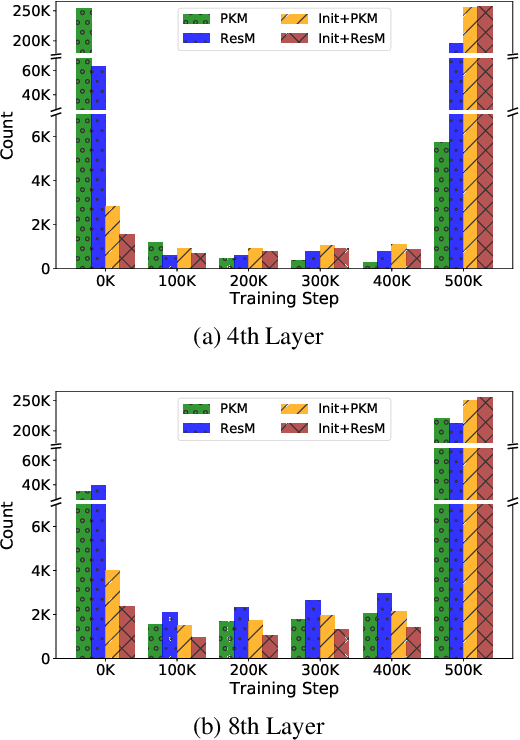
Product key memory (PKM) proposed by Lample et al. (2019) enables to improve prediction accuracy by increasing model capacity efficiently with insignificant computational overhead. However, their empirical application is only limited to causal language modeling. Motivated by the recent success of pretrained language models (PLMs), we investigate how to incorporate large PKM into PLMs that can be finetuned for a wide variety of downstream NLP tasks. We define a new memory usage metric, and careful observation using this metric reveals that most memory slots remain outdated during the training of PKM-augmented models. To train better PLMs by tackling this issue, we propose simple but effective solutions: (1) initialization from the model weights pretrained without memory and (2) augmenting PKM by addition rather than replacing a feed-forward network. We verify that both of them are crucial for the pretraining of PKM-augmented PLMs, enhancing memory utilization and downstream performance. Code and pretrained weights are available at https://github.com/clovaai/pkm-transformers.