 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFunction approximation by deep networks
May 30, 2019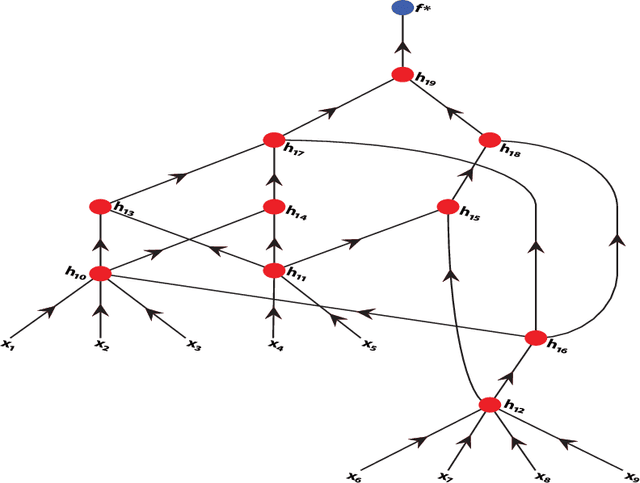

We show that deep networks are better than shallow networks at approximating functions that can be expressed as a composition of functions described by a directed acyclic graph, because the deep networks can be designed to have the same compositional structure, while a shallow network cannot exploit this knowledge. Thus, the blessing of compositionality mitigates the curse of dimensionality. On the other hand, a theorem called good propagation of errors allows to `lift' theorems about shallow networks to those about deep networks with an appropriate choice of norms, smoothness, etc. We illustrate this in three contexts where each channel in the deep network calculates a spherical polynomial, a non-smooth ReLU network, or another zonal function network related closely with the ReLU network.