 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredicting proximity with ambient mobile sensors for non-invasive health diagnostics
Dec 10, 2015



Modern smart phones are becoming helpful in the areas of Internet-Of-Things (IoT) and ambient health intelligence. By learning data from several mobile sensors, we detect nearness of the human body to a mobile device in a three-dimensional space with no physical contact with the device for non-invasive health diagnostics. We show that the human body generates wave patterns that interact with other naturally occurring ambient signals that could be measured by mobile sensors, such as, temperature, humidity, magnetic field, acceleration, gravity, and light. This interaction consequentially alters the patterns of the naturally occurring signals, and thus, exhibits characteristics that could be learned to predict the nearness of the human body to a mobile device, hence provide diagnostic information for medical practitioners. Our prediction technique achieved 88.75% accuracy and 88.3% specificity.
Learning Linguistic Biomarkers for Predicting Mild Cognitive Impairment using Compound Skip-grams
Dec 10, 2015

Predicting Mild Cognitive Impairment (MCI) is currently a challenge as existing diagnostic criteria rely on neuropsychological examinations. Automated Machine Learning (ML) models that are trained on verbal utterances of MCI patients can aid diagnosis. Using a combination of skip-gram features, our model learned several linguistic biomarkers to distinguish between 19 patients with MCI and 19 healthy control individuals from the DementiaBank language transcript clinical dataset. Results show that a model with compound of skip-grams has better AUC and could help ML prediction on small MCI data sample.
Review-Level Sentiment Classification with Sentence-Level Polarity Correction
Nov 07, 2015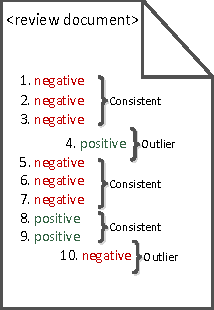
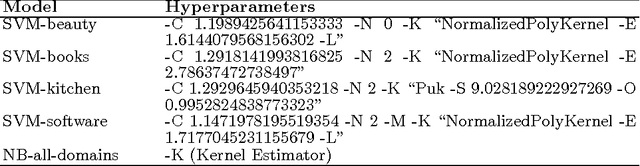
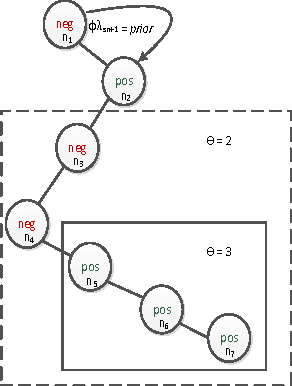
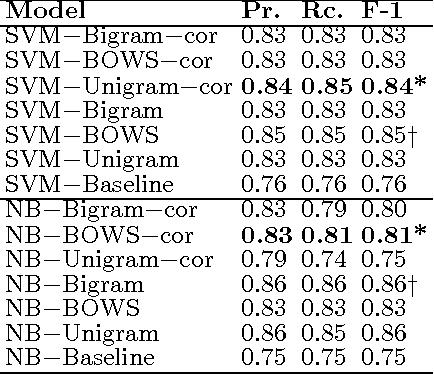
We propose an effective technique to solving review-level sentiment classification problem by using sentence-level polarity correction. Our polarity correction technique takes into account the consistency of the polarities (positive and negative) of sentences within each product review before performing the actual machine learning task. While sentences with inconsistent polarities are removed, sentences with consistent polarities are used to learn state-of-the-art classifiers. The technique achieved better results on different types of products reviews and outperforms baseline models without the correction technique. Experimental results show an average of 82% F-measure on four different product review domains.