 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistributed Learning and its Application for Time-Series Prediction
Jun 10, 2021
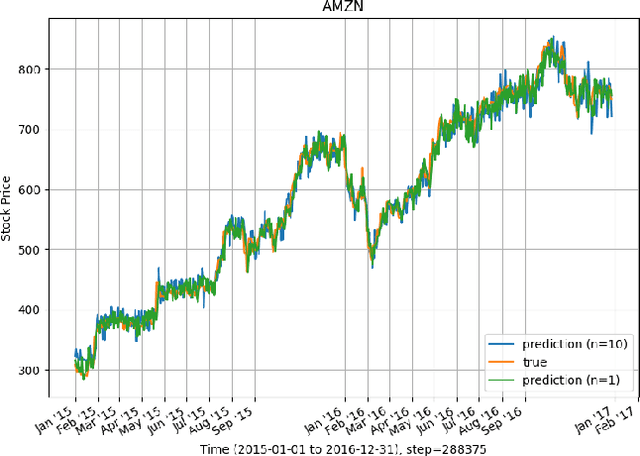

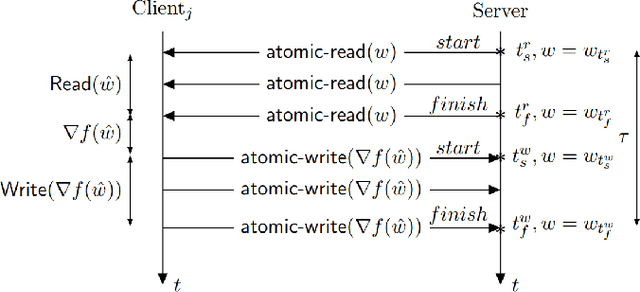
Extreme events are occurrences whose magnitude and potential cause extensive damage on people, infrastructure, and the environment. Motivated by the extreme nature of the current global health landscape, which is plagued by the coronavirus pandemic, we seek to better understand and model extreme events. Modeling extreme events is common in practice and plays an important role in time-series prediction applications. Our goal is to (i) compare and investigate the effect of some common extreme events modeling methods to explore which method can be practical in reality and (ii) accelerate the deep learning training process, which commonly uses deep recurrent neural network (RNN), by implementing the asynchronous local Stochastic Gradient Descent (SGD) framework among multiple compute nodes. In order to verify our distributed extreme events modeling, we evaluate our proposed framework on a stock data set S\&P500, with a standard recurrent neural network. Our intuition is to explore the (best) extreme events modeling method which could work well under the distributed deep learning setting. Moreover, by using asynchronous distributed learning, we aim to significantly reduce the communication cost among the compute nodes and central server, which is the main bottleneck of almost all distributed learning frameworks. We implement our proposed work and evaluate its performance on representative data sets, such as S&P500 stock in $5$-year period. The experimental results validate the correctness of the design principle and show a significant training duration reduction upto $8$x, compared to the baseline single compute node. Our results also show that our proposed work can achieve the same level of test accuracy, compared to the baseline setting.