 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRCAP: Robust, Class-Aware, Probabilistic Dynamic Dataset Pruning
Jun 10, 2026Dynamic data pruning techniques aim to reduce computational cost while minimizing information loss by periodically selecting representative subsets of input data during model training. However, existing methods often struggle to maintain strong worst-group accuracy, particularly at high pruning rates, across balanced and imbalanced datasets. To address this challenge, we propose RCAP, a Robust, Class-Aware, Probabilistic dynamic dataset pruning algorithm for classification tasks. RCAP applies a closed-form solution to estimate the fraction of samples to be included in the training subset for each individual class. This fraction is adaptively adjusted in every epoch using class-wise aggregated loss. Thereafter, it employs an adaptive sampling strategy that prioritizes samples having high loss for populating the class-wise subsets. We evaluate RCAP on six diverse datasets ranging from class-balanced to highly imbalanced using five distinct models across three training paradigms: training from scratch, transfer learning, and fine-tuning. Our approach consistently outperforms state-of-the-art dataset pruning methods, achieving superior worst-group accuracy at all pruning rates. Remarkably, with only $10\%$ data, RCAP delivers $>1\%$ improvement in performance on class-imbalanced datasets compared to full data training while providing an average $8.69\times$ speedup. The code can be accessed at https://github.com/atif-hassan/RCAP-dynamic-dataset-pruning
* Proceedings of the Forty-first Conference on Uncertainty in Artificial Intelligence (UAI 2025)
Verifiable and Energy Efficient Medical Image Analysis with Quantised Self-attentive Deep Neural Networks
Sep 30, 2022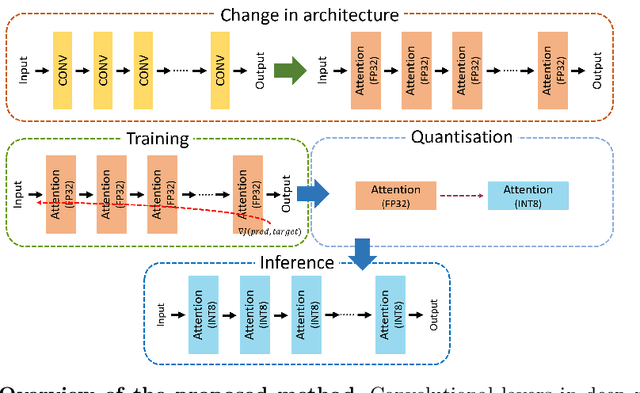

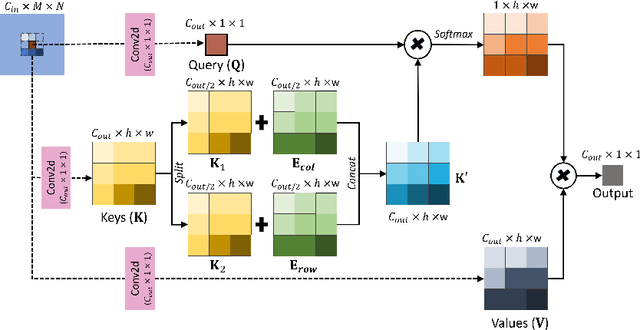

Convolutional Neural Networks have played a significant role in various medical imaging tasks like classification and segmentation. They provide state-of-the-art performance compared to classical image processing algorithms. However, the major downside of these methods is the high computational complexity, reliance on high-performance hardware like GPUs and the inherent black-box nature of the model. In this paper, we propose quantised stand-alone self-attention based models as an alternative to traditional CNNs. In the proposed class of networks, convolutional layers are replaced with stand-alone self-attention layers, and the network parameters are quantised after training. We experimentally validate the performance of our method on classification and segmentation tasks. We observe a $50-80\%$ reduction in model size, $60-80\%$ lesser number of parameters, $40-85\%$ fewer FLOPs and $65-80\%$ more energy efficiency during inference on CPUs. The code will be available at \href {https://github.com/Rakshith2597/Quantised-Self-Attentive-Deep-Neural-Network}{https://github.com/Rakshith2597/Quantised-Self-Attentive-Deep-Neural-Network}.
PPFS: Predictive Permutation Feature Selection
Oct 20, 2021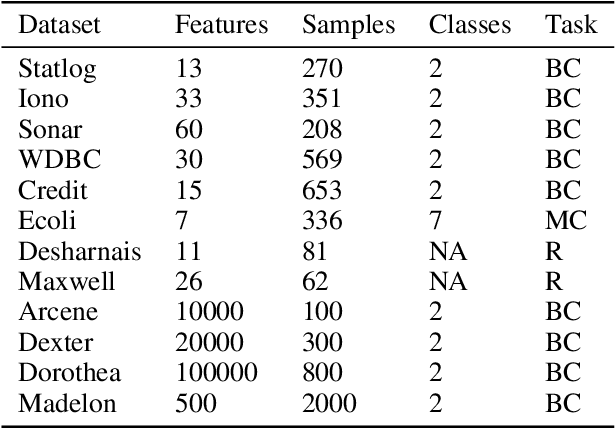
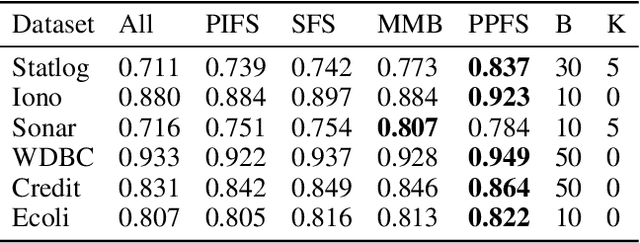
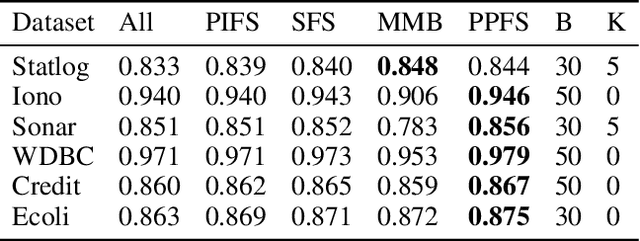
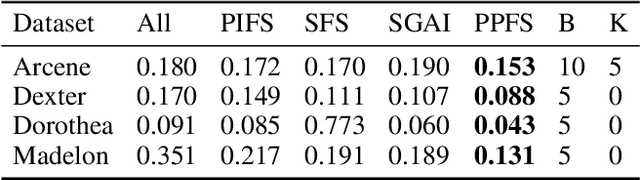
We propose Predictive Permutation Feature Selection (PPFS), a novel wrapper-based feature selection method based on the concept of Markov Blanket (MB). Unlike previous MB methods, PPFS is a universal feature selection technique as it can work for both classification as well as regression tasks on datasets containing categorical and/or continuous features. We propose Predictive Permutation Independence (PPI), a new Conditional Independence (CI) test, which enables PPFS to be categorised as a wrapper feature selection method. This is in contrast to current filter based MB feature selection techniques that are unable to harness the advancements in supervised algorithms such as Gradient Boosting Machines (GBM). The PPI test is based on the knockoff framework and utilizes supervised algorithms to measure the association between an individual or a set of features and the target variable. We also propose a novel MB aggregation step that addresses the issue of sample inefficiency. Empirical evaluations and comparisons on a large number of datasets demonstrate that PPFS outperforms state-of-the-art Markov blanket discovery algorithms as well as, well-known wrapper methods. We also provide a sketch of the proof of correctness of our method. Implementation of this work is available at \url{https://github.com/atif-hassan/PyImpetus}