 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMERLIon CCS Challenge Evaluation Plan
May 31, 2023



This paper introduces the inaugural Multilingual Everyday Recordings- Language Identification on Code-Switched Child-Directed Speech (MERLIon CCS) Challenge, focused on developing robust language identification and language diarization systems that are reliable for non-standard, accented, spontaneous code-switched, child-directed speech collected via Zoom. Aligning closely with Interspeech 2023 theme, the main objectives of this inaugural challenge are to present a unique first-of-its-kind Zoom videocall dataset featuring English-Mandarin spontaneous code-switched child-directed speech, benchmark the current and novel language identification and language diarization systems in a code-switching scenario including extremely short utterances, and test the robustness of such systems under accented speech. The MERLIon CCS challenge features two task: language identification (Task 1) and language diarization (Task 2). Two tracks, open and closed, are available for each task, differing by the volume of data systems can be trained on. This paper describes the dataset, dataset annotation protocol, challenge tasks, open and closed tracks, evaluation metrics, and evaluation protocol.
MERLIon CCS Challenge: A English-Mandarin code-switching child-directed speech corpus for language identification and diarization
May 30, 2023



To enhance the reliability and robustness of language identification (LID) and language diarization (LD) systems for heterogeneous populations and scenarios, there is a need for speech processing models to be trained on datasets that feature diverse language registers and speech patterns. We present the MERLIon CCS challenge, featuring a first-of-its-kind Zoom video call dataset of parent-child shared book reading, of over 30 hours with over 300 recordings, annotated by multilingual transcribers using a high-fidelity linguistic transcription protocol. The audio corpus features spontaneous and in-the-wild English-Mandarin code-switching, child-directed speech in non-standard accents with diverse language-mixing patterns recorded in a variety of home environments. This report describes the corpus, as well as LID and LD results for our baseline and several systems submitted to the MERLIon CCS challenge using the corpus.
Investigating model performance in language identification: beyond simple error statistics
May 30, 2023Language development experts need tools that can automatically identify languages from fluent, conversational speech, and provide reliable estimates of usage rates at the level of an individual recording. However, language identification systems are typically evaluated on metrics such as equal error rate and balanced accuracy, applied at the level of an entire speech corpus. These overview metrics do not provide information about model performance at the level of individual speakers, recordings, or units of speech with different linguistic characteristics. Overview statistics may therefore mask systematic errors in model performance for some subsets of the data, and consequently, have worse performance on data derived from some subsets of human speakers, creating a kind of algorithmic bias. In the current paper, we investigate how well a number of language identification systems perform on individual recordings and speech units with different linguistic properties in the MERLIon CCS Challenge. The Challenge dataset features accented English-Mandarin code-switched child-directed speech.
PHO-LID: A Unified Model Incorporating Acoustic-Phonetic and Phonotactic Information for Language Identification
Mar 31, 2022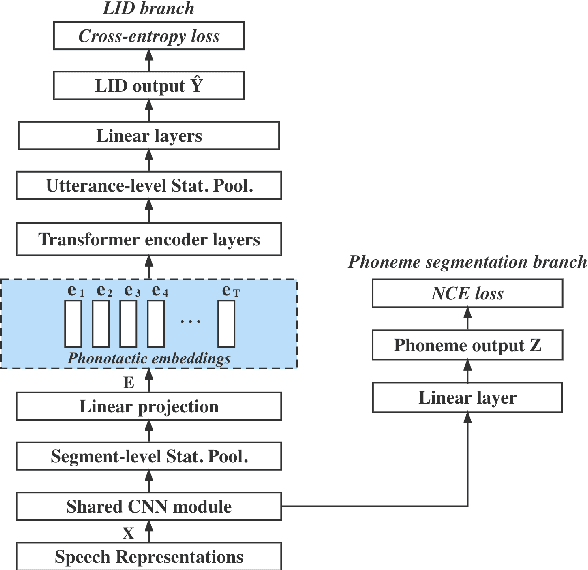
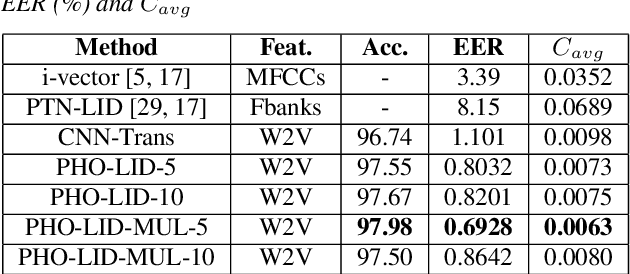
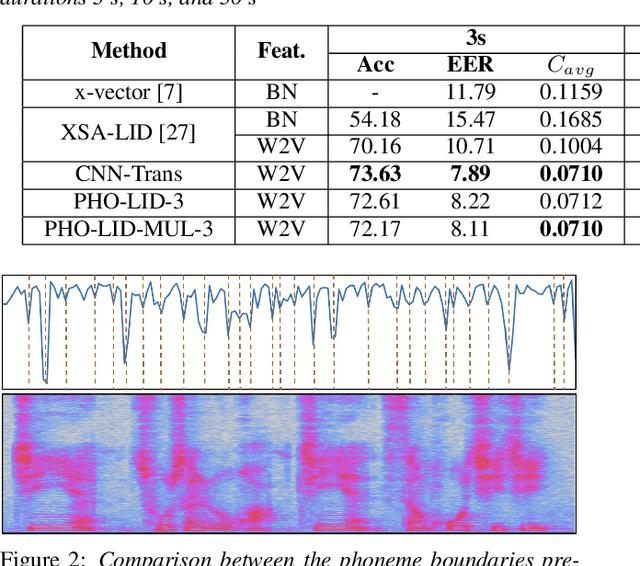
We propose a novel model to hierarchically incorporate phoneme and phonotactic information for language identification (LID) without requiring phoneme annotations for training. In this model, named PHO-LID, a self-supervised phoneme segmentation task and a LID task share a convolutional neural network (CNN) module, which encodes both language identity and sequential phonemic information in the input speech to generate an intermediate sequence of phonotactic embeddings. These embeddings are then fed into transformer encoder layers for utterance-level LID. We call this architecture CNN-Trans. We evaluate it on AP17-OLR data and the MLS14 set of NIST LRE 2017, and show that the PHO-LID model with multi-task optimization exhibits the highest LID performance among all models, achieving over 40% relative improvement in terms of average cost on AP17-OLR data compared to a CNN-Trans model optimized only for LID. The visualized confusion matrices imply that our proposed method achieves higher performance on languages of the same cluster in NIST LRE 2017 data than the CNN-Trans model. A comparison between predicted phoneme boundaries and corresponding audio spectrograms illustrates the leveraging of phoneme information for LID.
Enhance Language Identification using Dual-mode Model with Knowledge Distillation
Mar 07, 2022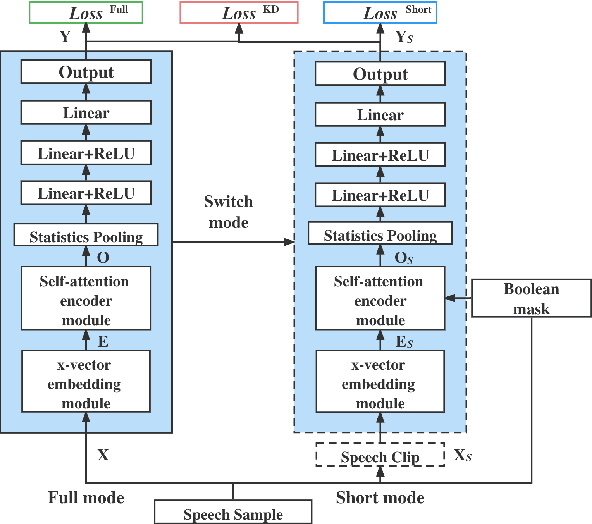
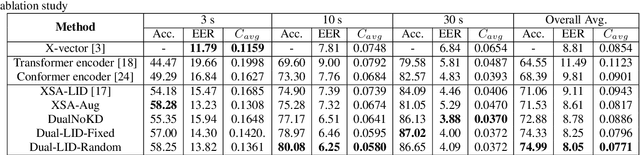

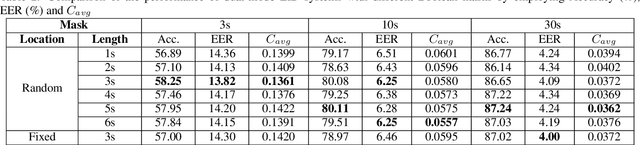
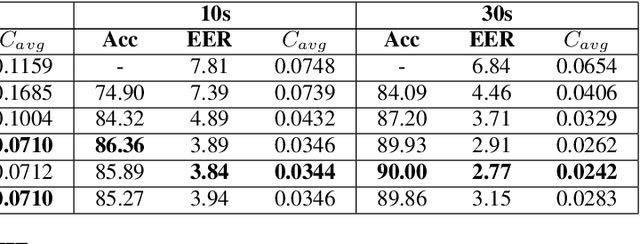
In this paper, we propose to employ a dual-mode framework on the x-vector self-attention (XSA-LID) model with knowledge distillation (KD) to enhance its language identification (LID) performance for both long and short utterances. The dual-mode XSA-LID model is trained by jointly optimizing both the full and short modes with their respective inputs being the full-length speech and its short clip extracted by a specific Boolean mask, and KD is applied to further boost the performance on short utterances. In addition, we investigate the impact of clip-wise linguistic variability and lexical integrity for LID by analyzing the variation of LID performance in terms of the lengths and positions of the mimicked speech clips. We evaluated our approach on the MLS14 data from the NIST 2017 LRE. With the 3~s random-location Boolean mask, our proposed method achieved 19.23%, 21.52% and 8.37% relative improvement in average cost compared with the XSA-LID model on 3s, 10s, and 30s speech, respectively.