 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRestructuring Batch Normalization to Accelerate CNN Training
Jul 04, 2018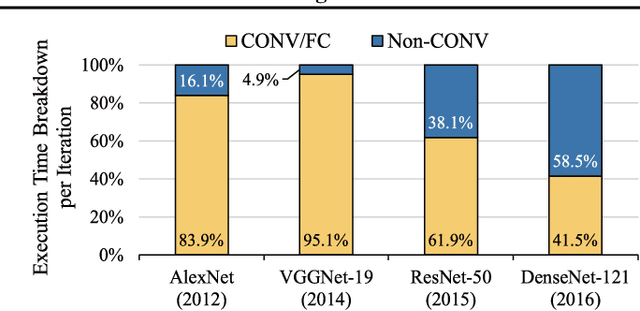
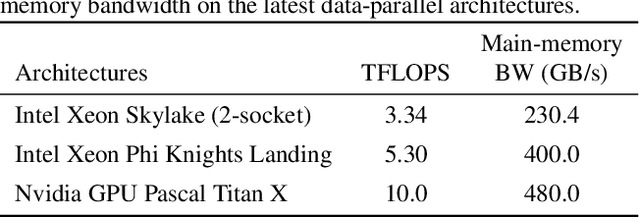
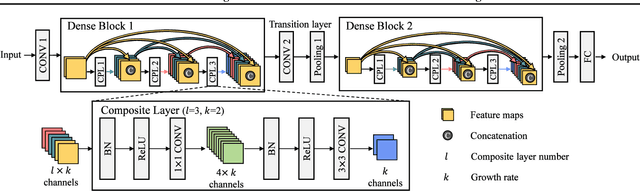
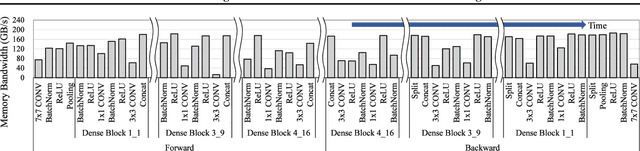
Because CNN models are compute-intensive, where billions of operations can be required just for an inference over a single input image, a variety of CNN accelerators have been proposed and developed. For the early CNN models, the research mostly focused on convolutional and fully-connected layers because the two layers consumed most of the computation cycles. For more recent CNN models, however, non-convolutional layers have become comparably important because of the popular use of newly designed non-convolutional layers and because of the reduction in the number and size of convolutional filters. Non-convolutional layers, including batch normalization (BN), typically have relatively lower computational intensity compared to the convolutional or fully-connected layers, and hence are often constrained by main-memory bandwidth. In this paper, we focus on accelerating the BN layers among the non-convolutional layers, as BN has become a core design block of modern CNNs. A typical modern CNN has a large number of BN layers. BN requires mean and variance calculations over each mini-batch during training. Therefore, the existing memory-access reduction techniques, such as fusing multiple CONV layers, are not effective for accelerating BN due to their inability to optimize mini-batch related calculations. To address this increasingly important problem, we propose to restructure BN layers by first splitting it into two sub-layers and then combining the first sub-layer with its preceding convolutional layer and the second sub-layer with the following activation and convolutional layers. The proposed solution can significantly reduce main-memory accesses while training the latest CNN models, and the experiments on a chip multiprocessor with our modified Caffe implementation show that the proposed BN restructuring can improve the performance of DenseNet with 121 convolutional layers by 28.4%.