 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCamera Agnostic Two-Head Network for Ego-Lane Inference
Apr 19, 2024



Vision-based ego-lane inference using High-Definition (HD) maps is essential in autonomous driving and advanced driver assistance systems. The traditional approach necessitates well-calibrated cameras, which confines variation of camera configuration, as the algorithm relies on intrinsic and extrinsic calibration. In this paper, we propose a learning-based ego-lane inference by directly estimating the ego-lane index from a single image. To enhance robust performance, our model incorporates the two-head structure inferring ego-lane in two perspectives simultaneously. Furthermore, we utilize an attention mechanism guided by vanishing point-and-line to adapt to changes in viewpoint without requiring accurate calibration. The high adaptability of our model was validated in diverse environments, devices, and camera mounting points and orientations.
Line as a Visual Sentence: Context-aware Line Descriptor for Visual Localization
Sep 10, 2021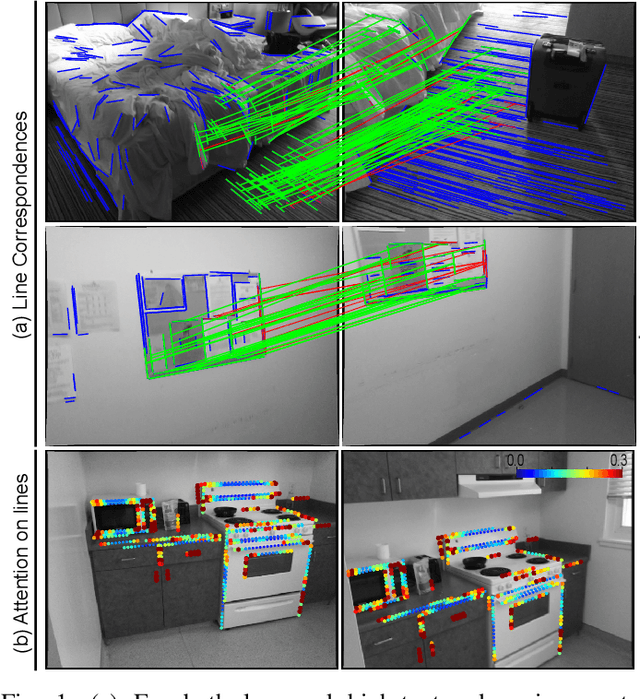
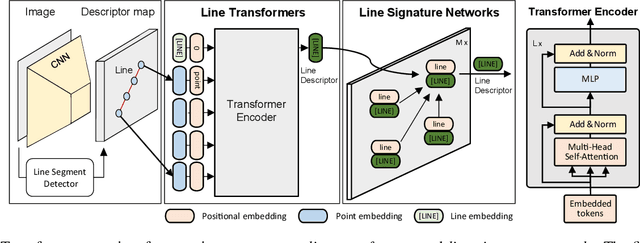
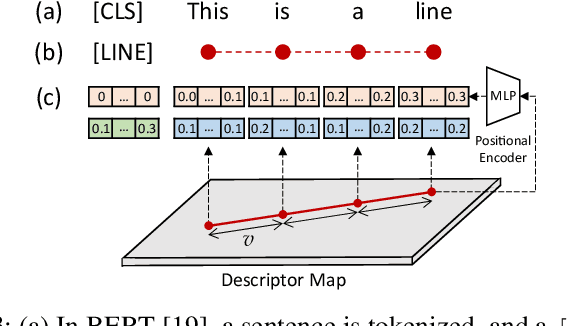
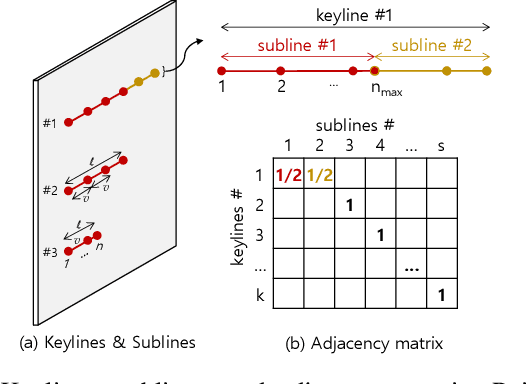
Along with feature points for image matching, line features provide additional constraints to solve visual geometric problems in robotics and computer vision (CV). Although recent convolutional neural network (CNN)-based line descriptors are promising for viewpoint changes or dynamic environments, we claim that the CNN architecture has innate disadvantages to abstract variable line length into the fixed-dimensional descriptor. In this paper, we effectively introduce Line-Transformers dealing with variable lines. Inspired by natural language processing (NLP) tasks where sentences can be understood and abstracted well in neural nets, we view a line segment as a sentence that contains points (words). By attending to well-describable points on aline dynamically, our descriptor performs excellently on variable line length. We also propose line signature networks sharing the line's geometric attributes to neighborhoods. Performing as group descriptors, the networks enhance line descriptors by understanding lines' relative geometries. Finally, we present the proposed line descriptor and matching in a Point and Line Localization (PL-Loc). We show that the visual localization with feature points can be improved using our line features. We validate the proposed method for homography estimation and visual localization.
Balanced Depth Completion between Dense Depth Inference and Sparse Range Measurements via KISS-GP
Aug 12, 2020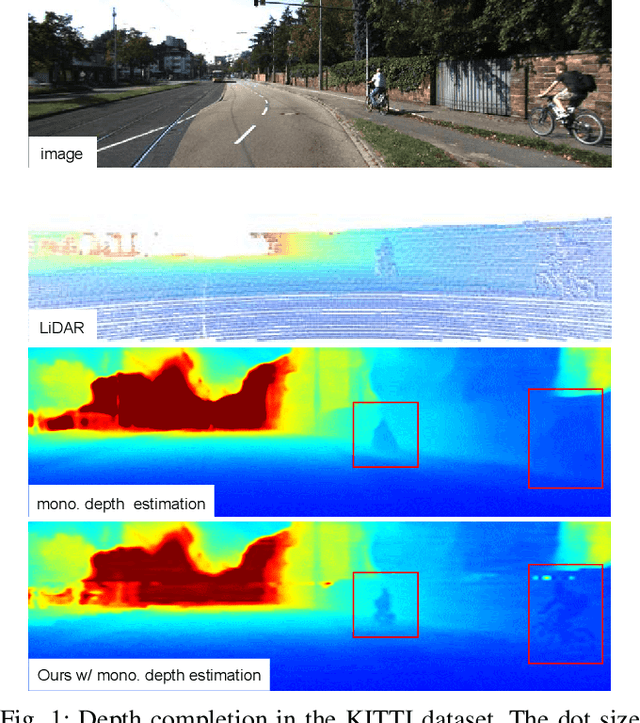
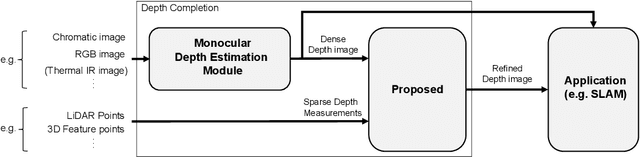
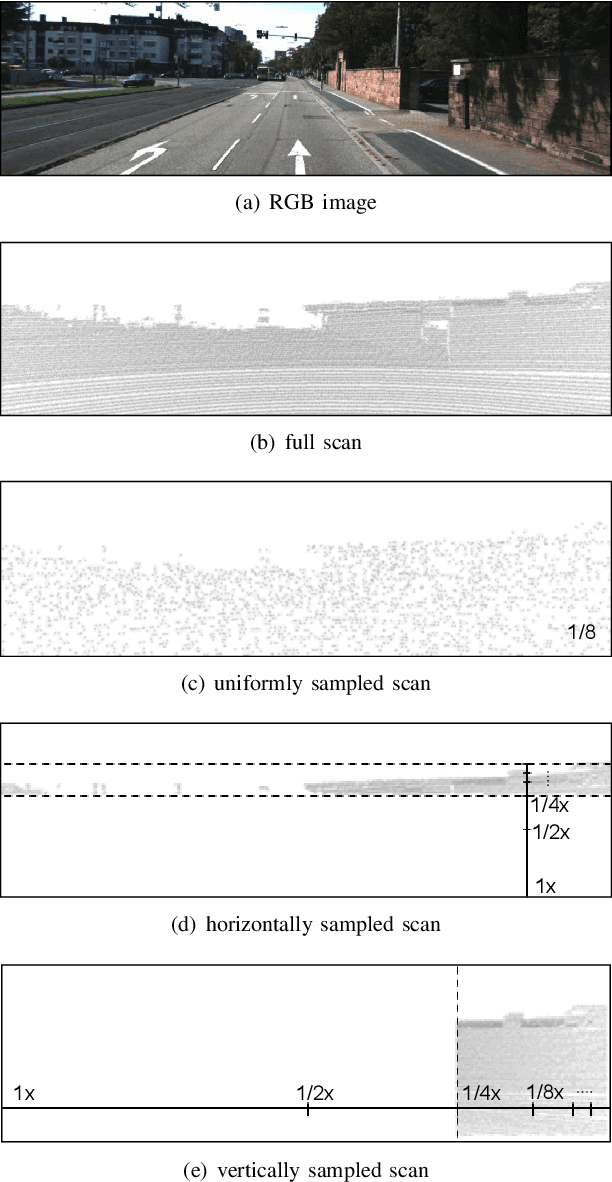
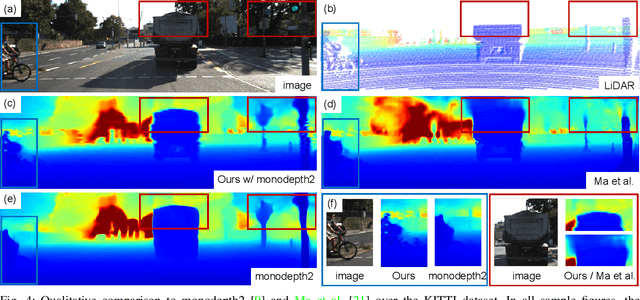
Estimating a dense and accurate depth map is the key requirement for autonomous driving and robotics. Recent advances in deep learning have allowed depth estimation in full resolution from a single image. Despite this impressive result, many deep-learning-based monocular depth estimation (MDE) algorithms have failed to keep their accuracy yielding a meter-level estimation error. In many robotics applications, accurate but sparse measurements are readily available from Light Detection and Ranging (LiDAR). Although they are highly accurate, the sparsity limits full resolution depth map reconstruction. Targeting the problem of dense and accurate depth map recovery, this paper introduces the fusion of these two modalities as a depth completion (DC) problem by dividing the role of depth inference and depth regression. Utilizing the state-of-the-art MDE and our Gaussian process (GP) based depth-regression method, we propose a general solution that can flexibly work with various MDE modules by enhancing its depth with sparse range measurements. To overcome the major limitation of GP, we adopt Kernel Interpolation for Scalable Structured (KISS)-GP and mitigate the computational complexity from O(N^3) to O(N). Our experiments demonstrate that the accuracy and robustness of our method outperform state-of-the-art unsupervised methods for sparse and biased measurements.