 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLAVA: Language Audio Vision Alignment for Contrastive Video Pre-Training
Jul 16, 2022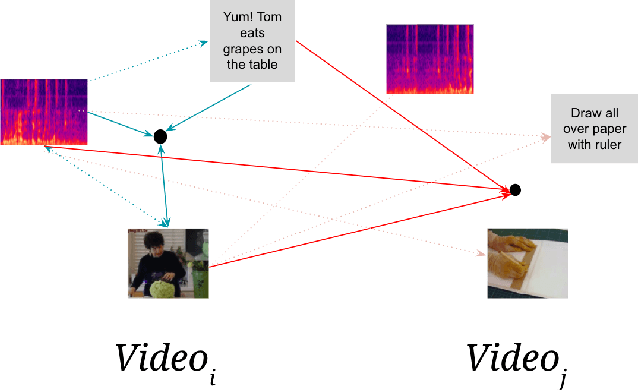



Generating representations of video data is of key importance in advancing the field of machine perception. Most current techniques rely on hand-annotated data, which can be difficult to work with, expensive to generate, and hard to scale. In this work, we propose a novel learning approach based on contrastive learning, LAVA, which is capable of learning joint language, audio, and video representations in a self-supervised manner. We pre-train LAVA on the Kinetics 700 dataset using transformer encoders to learn representations for each modality. We then demonstrate that LAVA performs competitively with the current state-of-the-art self-supervised and weakly-supervised pretraining techniques on UCF-101 and HMDB-51 video action recognition while using a fraction of the unlabeled data.