 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMotionGlot: A Multi-Embodied Motion Generation Model
Oct 22, 2024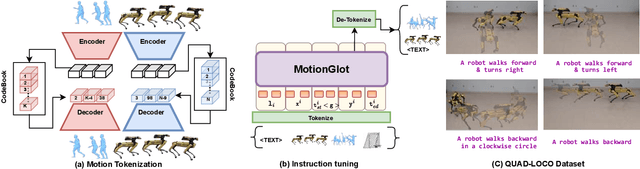
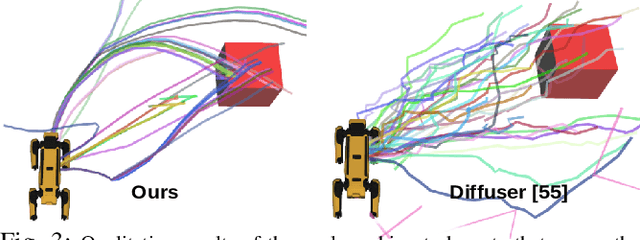
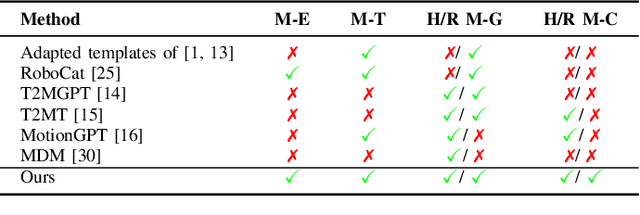
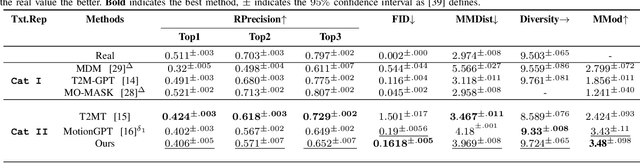
This paper introduces MotionGlot, a model that can generate motion across multiple embodiments with different action dimensions, such as quadruped robots and human bodies. By leveraging the well-established training procedures commonly used in large language models (LLMs), we introduce an instruction-tuning template specifically designed for motion-related tasks. Our approach demonstrates that the principles underlying LLM training can be successfully adapted to learn a wide range of motion generation tasks across multiple embodiments with different action dimensions. We demonstrate the various abilities of MotionGlot on a set of 6 tasks and report an average improvement of 35.3% across tasks. Additionally, we contribute two new datasets: (1) a dataset of expert-controlled quadruped locomotion with approximately 48,000 trajectories paired with direction-based text annotations, and (2) a dataset of over 23,000 situational text prompts for human motion generation tasks. Finally, we conduct hardware experiments to validate the capabilities of our system in real-world applications.