 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGuess What Moves: Unsupervised Video and Image Segmentation by Anticipating Motion
May 16, 2022
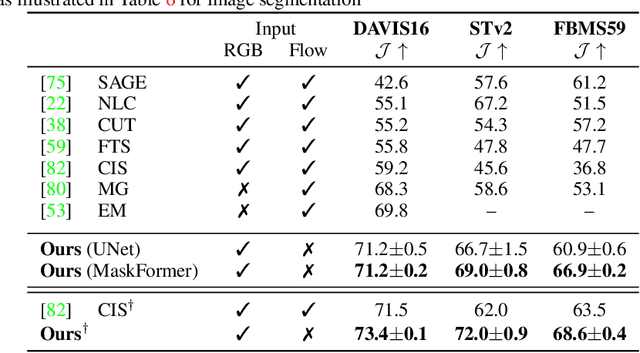

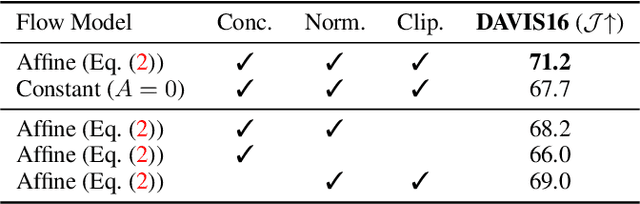
Motion, measured via optical flow, provides a powerful cue to discover and learn objects in images and videos. However, compared to using appearance, it has some blind spots, such as the fact that objects become invisible if they do not move. In this work, we propose an approach that combines the strengths of motion-based and appearance-based segmentation. We propose to supervise an image segmentation network, tasking it with predicting regions that are likely to contain simple motion patterns, and thus likely to correspond to objects. We apply this network in two modes. In the unsupervised video segmentation mode, the network is trained on a collection of unlabelled videos, using the learning process itself as an algorithm to segment these videos. In the unsupervised image segmentation model, the network is learned using videos and applied to segment independent still images. With this, we obtain strong empirical results in unsupervised video and image segmentation, significantly outperforming the state of the art on benchmarks such as DAVIS, sometimes with a $5\%$ IoU gap.
Unsupervised Part Discovery from Contrastive Reconstruction
Nov 11, 2021
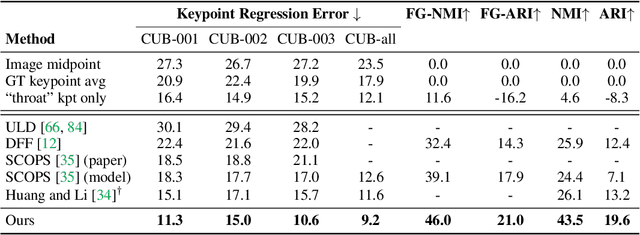


The goal of self-supervised visual representation learning is to learn strong, transferable image representations, with the majority of research focusing on object or scene level. On the other hand, representation learning at part level has received significantly less attention. In this paper, we propose an unsupervised approach to object part discovery and segmentation and make three contributions. First, we construct a proxy task through a set of objectives that encourages the model to learn a meaningful decomposition of the image into its parts. Secondly, prior work argues for reconstructing or clustering pre-computed features as a proxy to parts; we show empirically that this alone is unlikely to find meaningful parts; mainly because of their low resolution and the tendency of classification networks to spatially smear out information. We suggest that image reconstruction at the level of pixels can alleviate this problem, acting as a complementary cue. Lastly, we show that the standard evaluation based on keypoint regression does not correlate well with segmentation quality and thus introduce different metrics, NMI and ARI, that better characterize the decomposition of objects into parts. Our method yields semantic parts which are consistent across fine-grained but visually distinct categories, outperforming the state of the art on three benchmark datasets. Code is available at the project page: https://www.robots.ox.ac.uk/~vgg/research/unsup-parts/.
The Curious Layperson: Fine-Grained Image Recognition without Expert Labels
Nov 05, 2021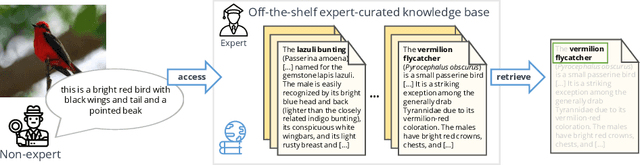
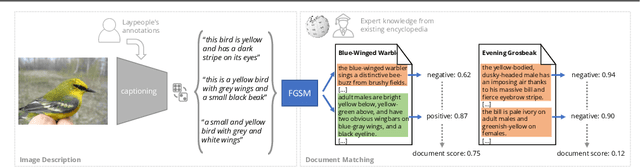
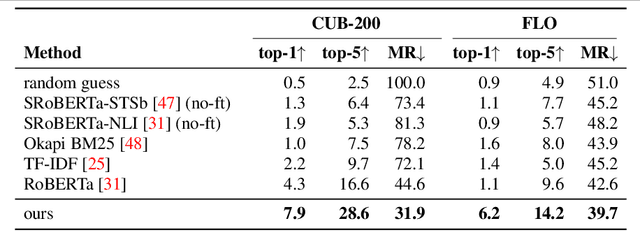
Most of us are not experts in specific fields, such as ornithology. Nonetheless, we do have general image and language understanding capabilities that we use to match what we see to expert resources. This allows us to expand our knowledge and perform novel tasks without ad-hoc external supervision. On the contrary, machines have a much harder time consulting expert-curated knowledge bases unless trained specifically with that knowledge in mind. Thus, in this paper we consider a new problem: fine-grained image recognition without expert annotations, which we address by leveraging the vast knowledge available in web encyclopedias. First, we learn a model to describe the visual appearance of objects using non-expert image descriptions. We then train a fine-grained textual similarity model that matches image descriptions with documents on a sentence-level basis. We evaluate the method on two datasets and compare with several strong baselines and the state of the art in cross-modal retrieval. Code is available at: https://github.com/subhc/clever