 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExtreme Value Monte Carlo Tree Search
May 28, 2024



Despite being successful in board games and reinforcement learning (RL), UCT, a Monte-Carlo Tree Search (MCTS) combined with UCB1 Multi-Armed Bandit (MAB), has had limited success in domain-independent planning until recently. Previous work showed that UCB1, designed for $[0,1]$-bounded rewards, is not appropriate for estimating the distance-to-go which are potentially unbounded in $\mathbb{R}$, such as heuristic functions used in classical planning, then proposed combining MCTS with MABs designed for Gaussian reward distributions and successfully improved the performance. In this paper, we further sharpen our understanding of ideal bandits for planning tasks. Existing work has two issues: First, while Gaussian MABs no longer over-specify the distances as $h\in [0,1]$, they under-specify them as $h\in [-\infty,\infty]$ while they are non-negative and can be further bounded in some cases. Second, there is no theoretical justifications for Full-Bellman backup (Schulte & Keller, 2014) that backpropagates minimum/maximum of samples. We identified \emph{extreme value} statistics as a theoretical framework that resolves both issues at once and propose two bandits, UCB1-Uniform/Power, and apply them to MCTS for classical planning. We formally prove their regret bounds and empirically demonstrate their performance in classical planning.
Scale-Adaptive Balancing of Exploration and Exploitation in Classical Planning
May 16, 2023
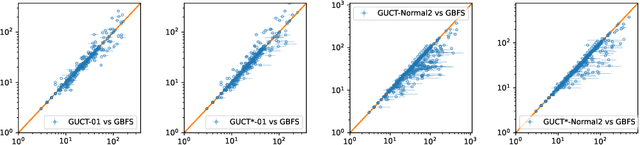
Balancing exploration and exploitation has been an important problem in both game tree search and automated planning. However, while the problem has been extensively analyzed within the Multi-Armed Bandit (MAB) literature, the planning community has had limited success when attempting to apply those results. We show that a more detailed theoretical understanding of MAB literature helps improve existing planning algorithms that are based on Monte Carlo Tree Search (MCTS) / Trial Based Heuristic Tree Search (THTS). In particular, THTS uses UCB1 MAB algorithms in an ad hoc manner, as UCB1's theoretical requirement of fixed bounded support reward distributions is not satisfied within heuristic search for classical planning. The core issue lies in UCB1's lack of adaptations to the different scales of the rewards. We propose GreedyUCT-Normal, a MCTS/THTS algorithm with UCB1-Normal bandit for agile classical planning, which handles distributions with different scales by taking the reward variance into consideration, and resulted in an improved algorithmic performance (more plans found with less node expansions) that outperforms Greedy Best First Search and existing MCTS/THTS-based algorithms (GreedyUCT,GreedyUCT*).