 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReasoning for Hierarchical Text Classification: The Case of Patents
Oct 08, 2025Hierarchical text classification (HTC) assigns documents to multiple levels of a pre-defined taxonomy. Automated patent subject classification represents one of the hardest HTC scenarios because of domain knowledge difficulty and a huge number of labels. Prior approaches only output a flat label set, which offers little insight into the reason behind predictions. Therefore, we propose Reasoning for Hierarchical Classification (RHC), a novel framework that reformulates HTC as a step-by-step reasoning task to sequentially deduce hierarchical labels. RHC trains large language models (LLMs) in two stages: a cold-start stage that aligns outputs with chain-of-thought (CoT) reasoning format and a reinforcement learning (RL) stage to enhance multi-step reasoning ability. RHC demonstrates four advantages in our experiments. (1) Effectiveness: RHC surpasses previous baselines and outperforms the supervised fine-tuning counterparts by approximately 3% in accuracy and macro F1. (2) Explainability: RHC produces natural-language justifications before prediction to facilitate human inspection. (3) Scalability: RHC scales favorably with model size with larger gains compared to standard fine-tuning. (4) Applicability: Beyond patents, we further demonstrate that RHC achieves state-of-the-art performance on other widely used HTC benchmarks, which highlights its broad applicability.
Enriching Patent Claim Generation with European Patent Dataset
May 18, 2025Drafting patent claims is time-intensive, costly, and requires professional skill. Therefore, researchers have investigated large language models (LLMs) to assist inventors in writing claims. However, existing work has largely relied on datasets from the United States Patent and Trademark Office (USPTO). To enlarge research scope regarding various jurisdictions, drafting conventions, and legal standards, we introduce EPD, a European patent dataset. EPD presents rich textual data and structured metadata to support multiple patent-related tasks, including claim generation. This dataset enriches the field in three critical aspects: (1) Jurisdictional diversity: Patents from different offices vary in legal and drafting conventions. EPD fills a critical gap by providing a benchmark for European patents to enable more comprehensive evaluation. (2) Quality improvement: EPD offers high-quality granted patents with finalized and legally approved texts, whereas others consist of patent applications that are unexamined or provisional. Experiments show that LLMs fine-tuned on EPD significantly outperform those trained on previous datasets and even GPT-4o in claim quality and cross-domain generalization. (3) Real-world simulation: We propose a difficult subset of EPD to better reflect real-world challenges of claim generation. Results reveal that all tested LLMs perform substantially worse on these challenging samples, which highlights the need for future research.
Towards Better Evaluation for Generated Patent Claims
May 16, 2025Patent claims define the scope of protection and establish the legal boundaries of an invention. Drafting these claims is a complex and time-consuming process that usually requires the expertise of skilled patent attorneys, which can form a large access barrier for many small enterprises. To solve these challenges, researchers have investigated the use of large language models (LLMs) for automating patent claim generation. However, existing studies highlight inconsistencies between automated evaluation metrics and human expert assessments. To bridge this gap, we introduce Patent-CE, the first comprehensive benchmark for evaluating patent claims. Patent-CE includes comparative claim evaluations annotated by patent experts, focusing on five key criteria: feature completeness, conceptual clarity, terminology consistency, logical linkage, and overall quality. Additionally, we propose PatClaimEval, a novel multi-dimensional evaluation method specifically designed for patent claims. Our experiments demonstrate that PatClaimEval achieves the highest correlation with human expert evaluations across all assessment criteria among all tested metrics. This research provides the groundwork for more accurate evaluations of automated patent claim generation systems.
Patent-CR: A Dataset for Patent Claim Revision
Dec 03, 2024



This paper presents Patent-CR, the first dataset created for the patent claim revision task in English. It includes both initial patent applications rejected by patent examiners and the final granted versions. Unlike normal text revision tasks that predominantly focus on enhancing sentence quality, such as grammar correction and coherence improvement, patent claim revision aims at ensuring the claims meet stringent legal criteria. These criteria are beyond novelty and inventiveness, including clarity of scope, technical accuracy, language precision, and legal robustness. We assess various large language models (LLMs) through professional human evaluation, including general LLMs with different sizes and architectures, text revision models, and domain-specific models. Our results indicate that LLMs often bring ineffective edits that deviate from the target revisions. In addition, domain-specific models and the method of fine-tuning show promising results. Notably, GPT-4 outperforms other tested LLMs, but further revisions are still necessary to reach the examination standard. Furthermore, we demonstrate the inconsistency between automated and human evaluation results, suggesting that GPT-4-based automated evaluation has the highest correlation with human judgment. This dataset, along with our preliminary empirical research, offers invaluable insights for further exploration in patent claim revision.
Can Large Language Models Generate High-quality Patent Claims?
Jun 27, 2024

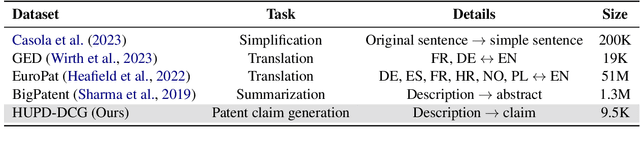

Large language models (LLMs) have shown exceptional performance across various text generation tasks but remain under-explored in the patent domain, which offers highly structured and precise language. This paper constructs a dataset to investigate the performance of current LLMs in patent claim generation. Our results demonstrate that generating claims based on patent descriptions outperforms previous research relying on abstracts. Interestingly, current patent-specific LLMs perform much worse than state-of-the-art general LLMs, highlighting the necessity for future research on in-domain LLMs. We also find that LLMs can produce high-quality first independent claims, but their performances markedly decrease for subsequent dependent claims. Moreover, fine-tuning can enhance the completeness of inventions' features, conceptual clarity, and feature linkage. Among the tested LLMs, GPT-4 demonstrates the best performance in comprehensive human evaluations by patent experts, with better feature coverage, conceptual clarity, and technical coherence. Despite these capabilities, comprehensive revision and modification are still necessary to pass rigorous patent scrutiny and ensure legal robustness.
Artificial Intelligence Exploring the Patent Field
Mar 06, 2024Advanced language-processing and machine-learning techniques promise massive efficiency improvements in the previously widely manual field of patent and technical knowledge management. This field presents large-scale and complex data with very precise contents and language representation of those contents. Particularly, patent texts can differ from mundane texts in various aspects, which entails significant opportunities and challenges. This paper presents a systematic overview of patent-related tasks and popular methodologies with a special focus on evolving and promising techniques. Language processing and particularly large language models as well as the recent boost of general generative methods promise to become game changers in the patent field. The patent literature and the fact-based argumentative procedures around patents appear almost as an ideal use case. However, patents entail a number of difficulties with which existing models struggle. The paper introduces fundamental aspects of patents and patent-related data that affect technology that wants to explore or manage them. It further reviews existing methods and approaches and points out how important reliable and unbiased evaluation metrics become. Although research has made substantial progress on certain tasks, the performance across many others remains suboptimal, sometimes because of either the special nature of patents and their language or inconsistencies between legal terms and the everyday meaning of terms. Moreover, yet few methods have demonstrated the ability to produce satisfactory text for specific sections of patents. By pointing out key developments, opportunities, and gaps, we aim to encourage further research and accelerate the advancement of this field.