 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNetwork Calculus with Flow Prolongation -- A Feedforward FIFO Analysis enabled by ML
Feb 07, 2022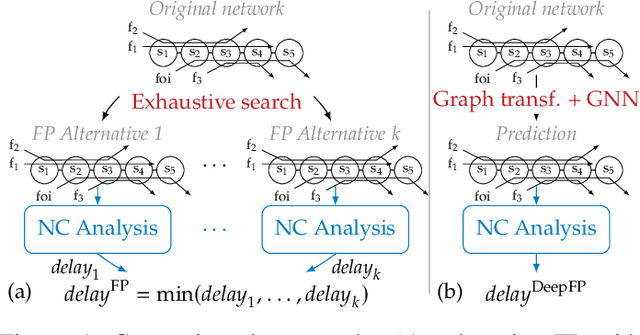

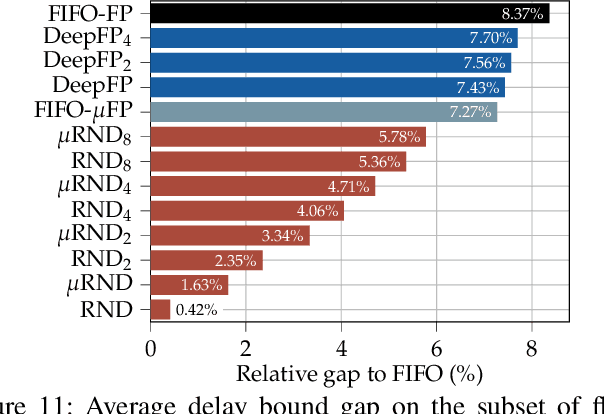
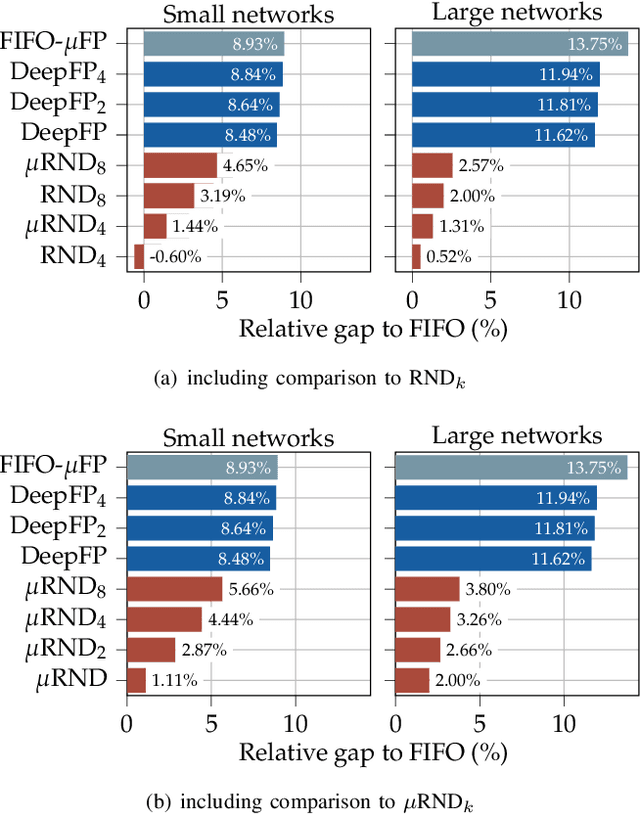
The derivation of upper bounds on data flows' worst-case traversal times is an important task in many application areas. For accurate bounds, model simplifications should be avoided even in large networks. Network Calculus (NC) provides a modeling framework and different analyses for delay bounding. We investigate the analysis of feedforward networks where all queues implement First-In First-Out (FIFO) service. Correctly considering the effect of data flows onto each other under FIFO is already a challenging task. Yet, the fastest available NC FIFO analysis suffers from limitations resulting in unnecessarily loose bounds. A feature called Flow Prolongation (FP) has been shown to improve delay bound accuracy significantly. Unfortunately, FP needs to be executed within the NC FIFO analysis very often and each time it creates an exponentially growing set of alternative networks with prolongations. FP therefore does not scale and has been out of reach for the exhaustive analysis of large networks. We introduce DeepFP, an approach to make FP scale by predicting prolongations using machine learning. In our evaluation, we show that DeepFP can improve results in FIFO networks considerably. Compared to the standard NC FIFO analysis, DeepFP reduces delay bounds by 12.1% on average at negligible additional computational cost.
On the Robustness of Deep Learning-predicted Contention Models for Network Calculus
Nov 24, 2019
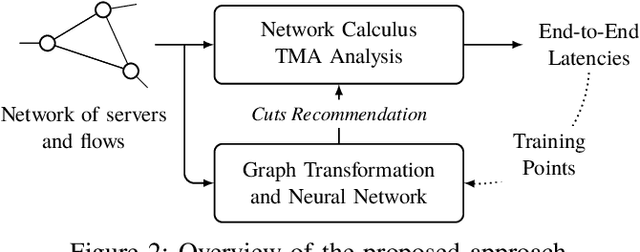
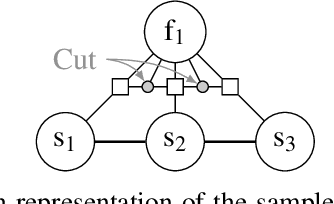
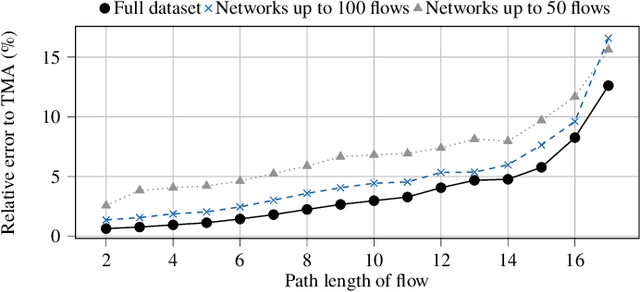
The network calculus (NC) analysis takes a simple model consisting of a network of schedulers and data flows crossing them. A number of analysis "building blocks" can then be applied to capture the model without imposing pessimistic assumptions like self-contention on tandems of servers. Yet, adding pessimism cannot always be avoided. To compute the best bound on a single flow's end-to-end delay thus boils down to finding the least pessimistic contention models for all tandems of schedulers in the network - and an exhaustive search can easily become a very resource intensive task. The literature proposes a promising solution to this dilemma: a heuristic making use of machine learning (ML) predictions inside the NC analysis. While results of this work are promising in terms of delay bound quality and computational effort, there is little to no insight on why a prediction is made or if the trained machine can achieve similarly striking results in networks vastly differing from its training data. In this paper we address these pending questions. We evaluate the influence of the training data and its features on accuracy, impact and scalability. Additionally, we contribute an extension of the method by predicting the best $n$ contention model alternatives in order to achieve increased robustness for its application outside the training data. Our numerical evaluation shows that good accuracy can still be achieved on large networks although we restrict the training to networks that are two orders of magnitude smaller.