 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlternate Training of Shared and Task-Specific Parameters for Multi-Task Neural Networks
Dec 26, 2023

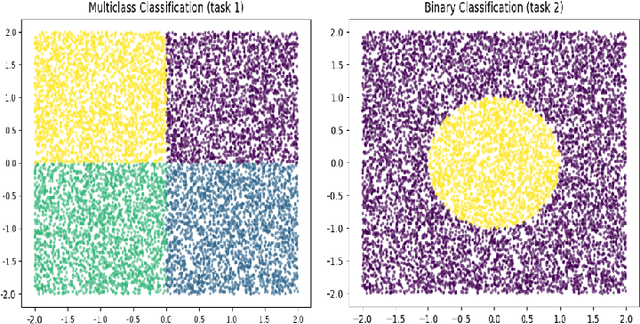

This paper introduces novel alternate training procedures for hard-parameter sharing Multi-Task Neural Networks (MTNNs). Traditional MTNN training faces challenges in managing conflicting loss gradients, often yielding sub-optimal performance. The proposed alternate training method updates shared and task-specific weights alternately, exploiting the multi-head architecture of the model. This approach reduces computational costs, enhances training regularization, and improves generalization. Convergence properties similar to those of the classical stochastic gradient method are established. Empirical experiments demonstrate delayed overfitting, improved prediction, and reduced computational demands. In summary, our alternate training procedures offer a promising advancement for the training of hard-parameter sharing MTNNs.