 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeObjective-Based Hierarchical Clustering of Deep Embedding Vectors
Dec 15, 2020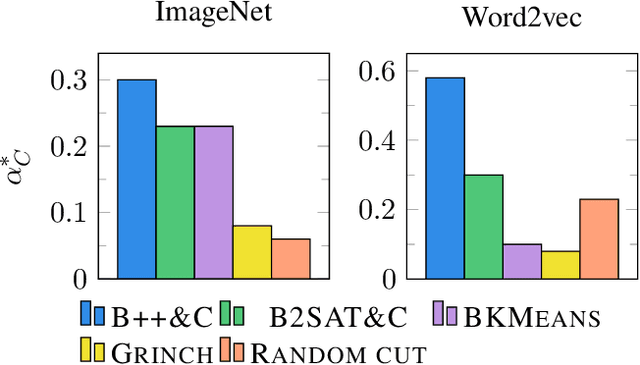
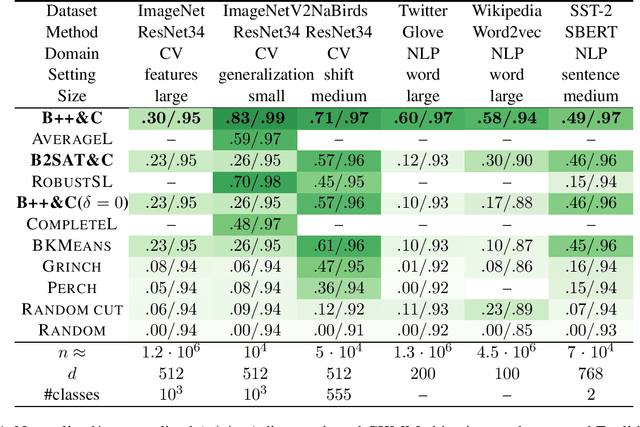
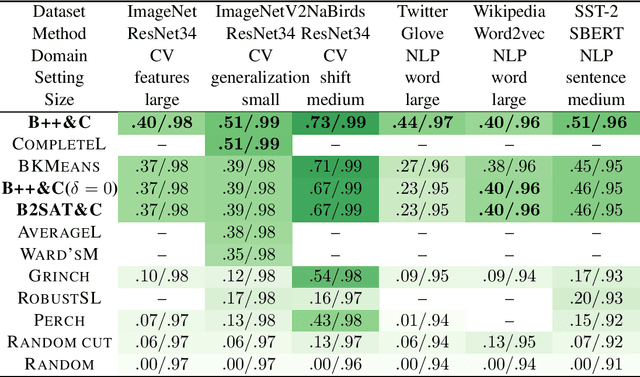
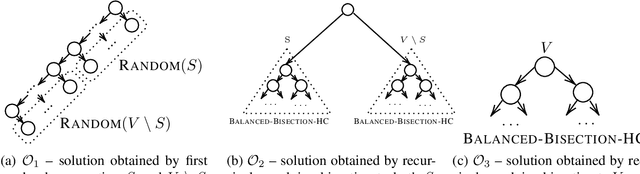
We initiate a comprehensive experimental study of objective-based hierarchical clustering methods on massive datasets consisting of deep embedding vectors from computer vision and NLP applications. This includes a large variety of image embedding (ImageNet, ImageNetV2, NaBirds), word embedding (Twitter, Wikipedia), and sentence embedding (SST-2) vectors from several popular recent models (e.g. ResNet, ResNext, Inception V3, SBERT). Our study includes datasets with up to $4.5$ million entries with embedding dimensions up to $2048$. In order to address the challenge of scaling up hierarchical clustering to such large datasets we propose a new practical hierarchical clustering algorithm B++&C. It gives a 5%/20% improvement on average for the popular Moseley-Wang (MW) / Cohen-Addad et al. (CKMM) objectives (normalized) compared to a wide range of classic methods and recent heuristics. We also introduce a theoretical algorithm B2SAT&C which achieves a $0.74$-approximation for the CKMM objective in polynomial time. This is the first substantial improvement over the trivial $2/3$-approximation achieved by a random binary tree. Prior to this work, the best poly-time approximation of $\approx 2/3 + 0.0004$ was due to Charikar et al. (SODA'19).