 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast Autofocusing using Tiny Transformer Networks for Digital Holographic Microscopy
Mar 30, 2022



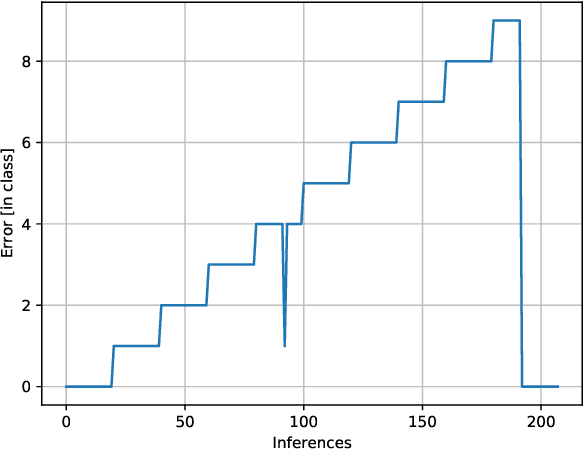
The numerical wavefront backpropagation principle of digital holography confers unique extended focus capabilities, without mechanical displacements along z-axis. However, the determination of the correct focusing distance is a non-trivial and time consuming issue. A deep learning (DL) solution is proposed to cast the autofocusing as a regression problem and tested over both experimental and simulated holograms. Single wavelength digital holograms were recorded by a Digital Holographic Microscope (DHM) with a 10$\mathrm{x}$ microscope objective from a patterned target moving in 3D over an axial range of 92 $\mu$m. Tiny DL models are proposed and compared such as a tiny Vision Transformer (TViT), tiny VGG16 (TVGG) and a tiny Swin-Transfomer (TSwinT). The experiments show that the predicted focusing distance $Z_R^{\mathrm{Pred}}$ is accurately inferred with an accuracy of 1.2 $\mu$m in average in comparison with the DHM depth of field of 15 $\mu$m. Numerical simulations show that all tiny models give the $Z_R^{\mathrm{Pred}}$ with an error below 0.3 $\mu$m. Such a prospect would significantly improve the current capabilities of computer vision position sensing in applications such as 3D microscopy for life sciences or micro-robotics. Moreover, all models reach state of the art inference time on CPU, less than 25 ms per inference.
Convolutional Neural Network (CNN) vs Visual Transformer (ViT) for Digital Holography
Aug 20, 2021

In Digital Holography (DH), it is crucial to extract the object distance from a hologram in order to reconstruct its amplitude and phase. This step is called auto-focusing and it is conventionally solved by first reconstructing a stack of images and then by sharpening each reconstructed image using a focus metric such as entropy or variance. The distance corresponding to the sharpest image is considered the focal position. This approach, while effective, is computationally demanding and time-consuming. In this paper, the determination of the distance is performed by Deep Learning (DL). Two deep learning (DL) architectures are compared: Convolutional Neural Network (CNN)and Visual transformer (ViT). ViT and CNN are used to cope with the problem of auto-focusing as a classification problem. Compared to a first attempt [11] in which the distance between two consecutive classes was 100{\mu}m, our proposal allows us to drastically reduce this distance to 1{\mu}m. Moreover, ViT reaches similar accuracy and is more robust than CNN.