 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDoc2Vec on the PubMed corpus: study of a new approach to generate related articles
Nov 26, 2019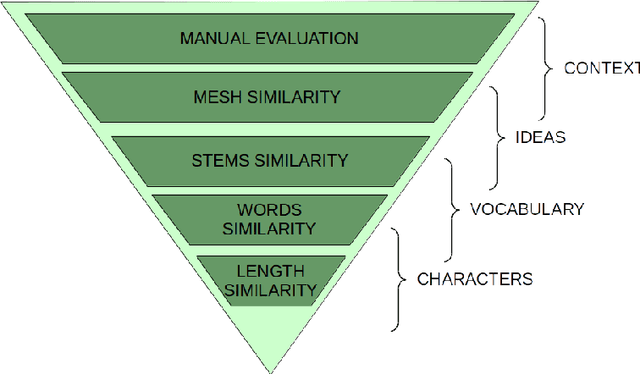

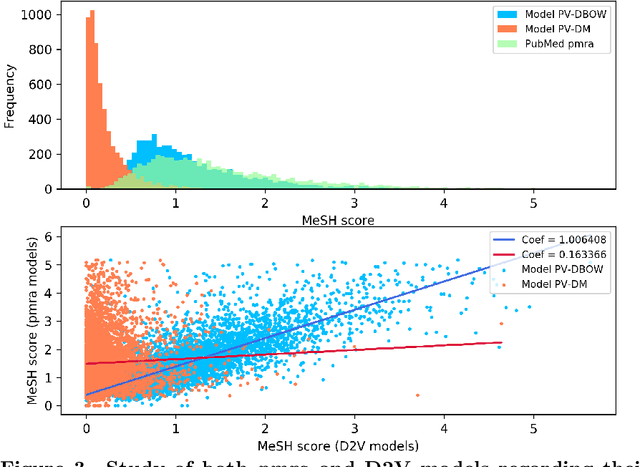

PubMed is the biggest and most used bibliographic database worldwide, hosting more than 26M biomedical publications. One of its useful features is the "similar articles" section, allowing the end-user to find scientific articles linked to the consulted document in term of context. The aim of this study is to analyze whether it is possible to replace the statistic model PubMed Related Articles (pmra) with a document embedding method. Doc2Vec algorithm was used to train models allowing to vectorize documents. Six of its parameters were optimised by following a grid-search strategy to train more than 1,900 models. Parameters combination leading to the best accuracy was used to train models on abstracts from the PubMed database. Four evaluations tasks were defined to determine what does or does not influence the proximity between documents for both Doc2Vec and pmra. The two different Doc2Vec architectures have different abilities to link documents about a common context. The terminological indexing, words and stems contents of linked documents are highly similar between pmra and Doc2Vec PV-DBOW architecture. These algorithms are also more likely to bring closer documents having a similar size. In contrary, the manual evaluation shows much better results for the pmra algorithm. While the pmra algorithm links documents by explicitly using terminological indexing in its formula, Doc2Vec does not need a prior indexing. It can infer relations between documents sharing a similar indexing, without any knowledge about them, particularly regarding the PV-DBOW architecture. In contrary, the human evaluation, without any clear agreement between evaluators, implies future studies to better understand this difference between PV-DBOW and pmra algorithm.