 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTom: Leveraging trend of the observed gradients for faster convergence
Sep 07, 2021
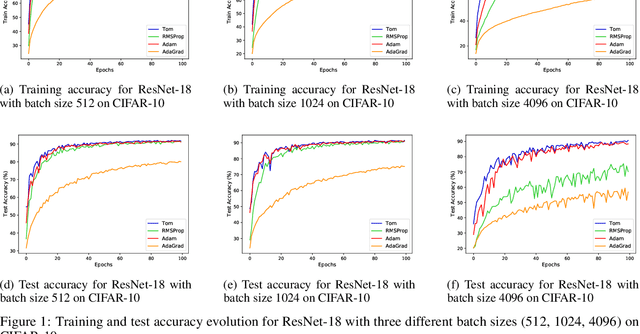
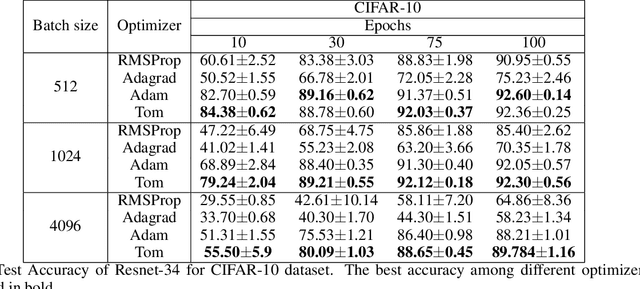

The success of deep learning can be attributed to various factors such as increase in computational power, large datasets, deep convolutional neural networks, optimizers etc. Particularly, the choice of optimizer affects the generalization, convergence rate, and training stability. Stochastic Gradient Descent (SGD) is a first order iterative optimizer that updates the gradient uniformly for all parameters. This uniform update may not be suitable across the entire training phase. A rudimentary solution for this is to employ a fine-tuned learning rate scheduler which decreases learning rate as a function of iteration. To eliminate the dependency of learning rate schedulers, adaptive gradient optimizers such as AdaGrad, AdaDelta, RMSProp, Adam employ a parameter-wise scaling term for learning rate which is a function of the gradient itself. We propose Tom (Trend over Momentum) optimizer, which is a novel variant of Adam that takes into account of the trend which is observed for the gradients in the loss landscape traversed by the neural network. In the proposed Tom optimizer, an additional smoothing equation is introduced to address the trend observed during the process of optimization. The smoothing parameter introduced for the trend requires no tuning and can be used with default values. Experimental results for classification datasets such as CIFAR-10, CIFAR-100 and CINIC-10 image datasets show that Tom outperforms Adagrad, Adadelta, RMSProp and Adam in terms of both accuracy and has a faster convergence. The source code is publicly made available at https://github.com/AnirudhMaiya/Tom