 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneralized SAM: Efficient Fine-Tuning of SAM for Variable Input Image Sizes
Aug 22, 2024There has been a lot of recent research on improving the efficiency of fine-tuning foundation models. In this paper, we propose a novel efficient fine-tuning method that allows the input image size of Segment Anything Model (SAM) to be variable. SAM is a powerful foundational model for image segmentation trained on huge datasets, but it requires fine-tuning to recognize arbitrary classes. The input image size of SAM is fixed at 1024 x 1024, resulting in substantial computational demands during training. Furthermore, the fixed input image size may result in the loss of image information, e.g. due to fixed aspect ratios. To address this problem, we propose Generalized SAM (GSAM). Different from the previous methods, GSAM is the first to apply random cropping during training with SAM, thereby significantly reducing the computational cost of training. Experiments on datasets of various types and various pixel counts have shown that GSAM can train more efficiently than SAM and other fine-tuning methods for SAM, achieving comparable or higher accuracy.
Lite-HRNet Plus: Fast and Accurate Facial Landmark Detection
Aug 23, 2023



Facial landmark detection is an essential technology for driver status tracking and has been in demand for real-time estimations. As a landmark coordinate prediction, heatmap-based methods are known to achieve a high accuracy, and Lite-HRNet can achieve a fast estimation. However, with Lite-HRNet, the problem of a heavy computational cost of the fusion block, which connects feature maps with different resolutions, has yet to be solved. In addition, the strong output module used in HRNetV2 is not applied to Lite-HRNet. Given these problems, we propose a novel architecture called Lite-HRNet Plus. Lite-HRNet Plus achieves two improvements: a novel fusion block based on a channel attention and a novel output module with less computational intensity using multi-resolution feature maps. Through experiments conducted on two facial landmark datasets, we confirmed that Lite-HRNet Plus further improved the accuracy in comparison with conventional methods, and achieved a state-of-the-art accuracy with a computational complexity with the range of 10M FLOPs.
Enlarged Large Margin Loss for Imbalanced Classification
Jun 15, 2023We propose a novel loss function for imbalanced classification. LDAM loss, which minimizes a margin-based generalization bound, is widely utilized for class-imbalanced image classification. Although, by using LDAM loss, it is possible to obtain large margins for the minority classes and small margins for the majority classes, the relevance to a large margin, which is included in the original softmax cross entropy loss, is not be clarified yet. In this study, we reconvert the formula of LDAM loss using the concept of the large margin softmax cross entropy loss based on the softplus function and confirm that LDAM loss includes a wider large margin than softmax cross entropy loss. Furthermore, we propose a novel Enlarged Large Margin (ELM) loss, which can further widen the large margin of LDAM loss. ELM loss utilizes the large margin for the maximum logit of the incorrect class in addition to the basic margin used in LDAM loss. Through experiments conducted on imbalanced CIFAR datasets and large-scale datasets with long-tailed distribution, we confirmed that classification accuracy was much improved compared with LDAM loss and conventional losses for imbalanced classification.
One-shot and Partially-Supervised Cell Image Segmentation Using Small Visual Prompt
Apr 17, 2023Semantic segmentation of microscopic cell images using deep learning is an important technique, however, it requires a large number of images and ground truth labels for training. To address the above problem, we consider an efficient learning framework with as little data as possible, and we propose two types of learning strategies: One-shot segmentation which can learn with only one training sample, and Partially-supervised segmentation which assigns annotations to only a part of images. Furthermore, we introduce novel segmentation methods using the small prompt images inspired by prompt learning in recent studies. Our proposed methods use a pre-trained model based on only cell images and teach the information of the prompt pairs to the target image to be segmented by the attention mechanism, which allows for efficient learning while reducing the burden of annotation costs. Through experiments conducted on three types of microscopic cell image datasets, we confirmed that the proposed method improved the Dice score coefficient (DSC) in comparison with the conventional methods.
Adaptive t-vMF Dice Loss for Multi-class Medical Image Segmentation
Jul 16, 2022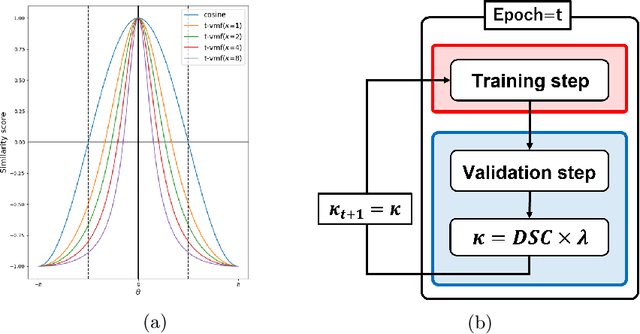
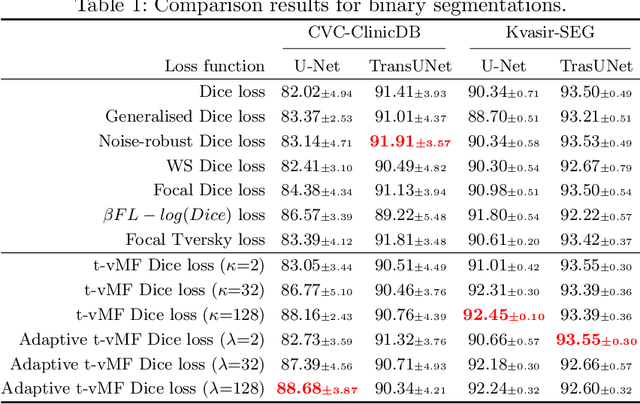
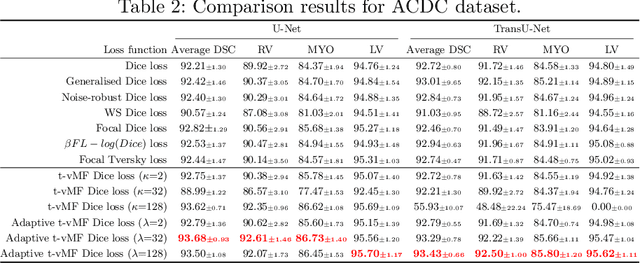
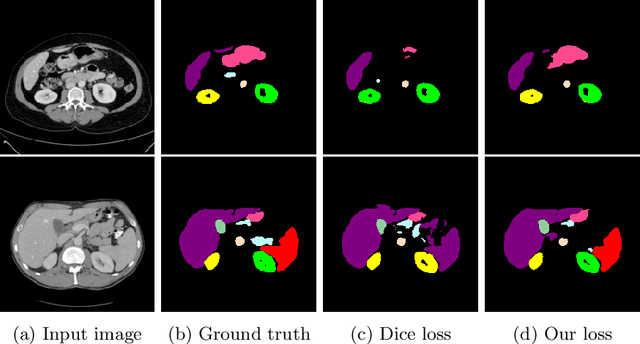
Dice loss is widely used for medical image segmentation, and many improvement loss functions based on such loss have been proposed. However, further Dice loss improvements are still possible. In this study, we reconsidered the use of Dice loss and discovered that Dice loss can be rewritten in the loss function using the cosine similarity through a simple equation transformation. Using this knowledge, we present a novel t-vMF Dice loss based on the t-vMF similarity instead of the cosine similarity. Based on the t-vMF similarity, our proposed Dice loss is formulated in a more compact similarity loss function than the original Dice loss. Furthermore, we present an effective algorithm that automatically determines the parameter $\kappa$ for the t-vMF similarity using a validation accuracy, called Adaptive t-vMf Dice loss. Using this algorithm, it is possible to apply more compact similarities for easy classes and wider similarities for difficult classes, and we are able to achieve an adaptive training based on the accuracy of the class. Through experiments conducted on four datasets using a five-fold cross validation, we confirmed that the Dice score coefficient (DSC) was further improved in comparison with the original Dice loss and other loss functions.
Automatic Preprocessing and Ensemble Learning for Low Quality Cell Image Segmentation
Aug 30, 2021
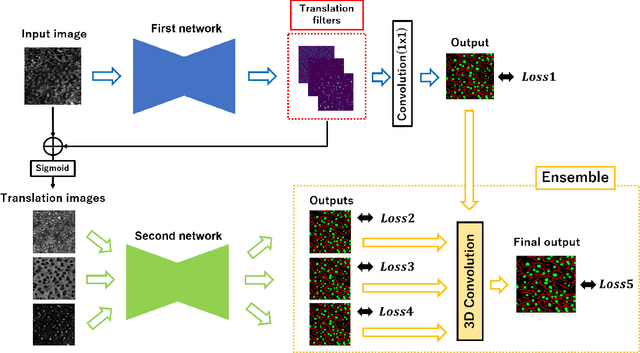
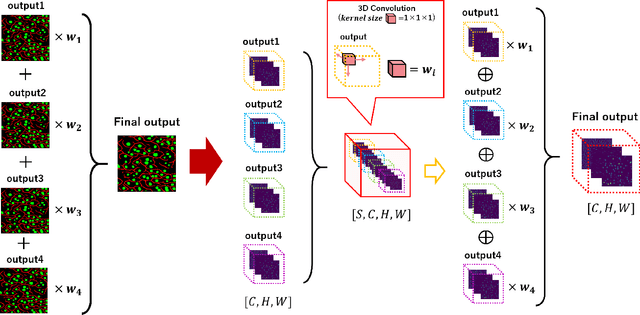
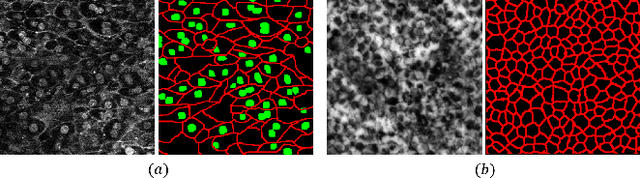
We propose an automatic preprocessing and ensemble learning for segmentation of cell images with low quality. It is difficult to capture cells with strong light. Therefore, the microscopic images of cells tend to have low image quality but these images are not good for semantic segmentation. Here we propose a method to translate an input image to the images that are easy to recognize by deep learning. The proposed method consists of two deep neural networks. The first network is the usual training for semantic segmentation, and penultimate feature maps of the first network are used as filters to translate an input image to the images that emphasize each class. This is the automatic preprocessing and translated cell images are easily classified. The input cell image with low quality is translated by the feature maps in the first network, and the translated images are fed into the second network for semantic segmentation. Since the outputs of the second network are multiple segmentation results, we conduct the weighted ensemble of those segmentation images. Two networks are trained by end-to-end manner, and we do not need to prepare images with high quality for the translation. We confirmed that our proposed method can translate cell images with low quality to the images that are easy to segment, and segmentation accuracy has improved using the weighted ensemble learning.
MSE Loss with Outlying Label for Imbalanced Classification
Jul 06, 2021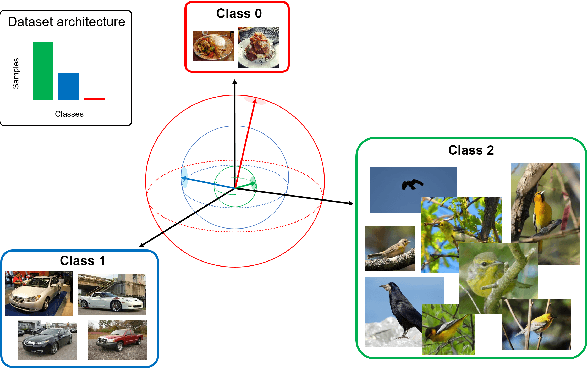

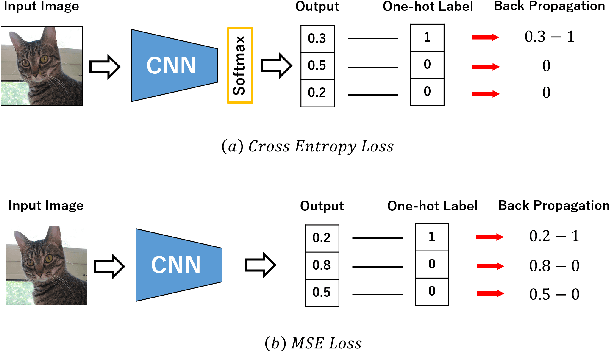

In this paper, we propose mean squared error (MSE) loss with outlying label for class imbalanced classification. Cross entropy (CE) loss, which is widely used for image recognition, is learned so that the probability value of true class is closer to one by back propagation. However, for imbalanced datasets, the learning is insufficient for the classes with a small number of samples. Therefore, we propose a novel classification method using the MSE loss that can be learned the relationships of all classes no matter which image is input. Unlike CE loss, MSE loss is possible to equalize the number of back propagation for all classes and to learn the feature space considering the relationships between classes as metric learning. Furthermore, instead of the usual one-hot teacher label, we use a novel teacher label that takes the number of class samples into account. This induces the outlying label which depends on the number of samples in each class, and the class with a small number of samples has outlying margin in a feature space. It is possible to create the feature space for separating high-difficulty classes and low-difficulty classes. By the experiments on imbalanced classification and semantic segmentation, we confirmed that the proposed method was much improved in comparison with standard CE loss and conventional methods, even though only the loss and teacher labels were changed.