 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLMs as Potential Brainstorming Partners for Math and Science Problems
Oct 10, 2023With the recent rise of widely successful deep learning models, there is emerging interest among professionals in various math and science communities to see and evaluate the state-of-the-art models' abilities to collaborate on finding or solving problems that often require creativity and thus brainstorming. While a significant chasm still exists between current human-machine intellectual collaborations and the resolution of complex math and science problems, such as the six unsolved Millennium Prize Problems, our initial investigation into this matter reveals a promising step towards bridging the divide. This is due to the recent advancements in Large Language Models (LLMs). More specifically, we conduct comprehensive case studies to explore both the capabilities and limitations of the current state-of-the-art LLM, notably GPT-4, in collective brainstorming with humans.
I Can't Believe There's No Images! Learning Visual Tasks Using only Language Data
Dec 01, 2022



Many high-level skills that are required for computer vision tasks, such as parsing questions, comparing and contrasting semantics, and writing descriptions, are also required in other domains such as natural language processing. In this paper, we ask whether this makes it possible to learn those skills from text data and then use them to complete vision tasks without ever training on visual training data. Key to our approach is exploiting the joint embedding space of contrastively trained vision and language encoders. In practice, there can be systematic differences between embedding spaces for different modalities in contrastive models, and we analyze how these differences affect our approach and study a variety of strategies to mitigate this concern. We produce models using only text training data on three tasks: image captioning, visual entailment and visual question answering, and evaluate them on standard benchmarks using images. We find that this kind of transfer is possible and results in only a small drop in performance relative to models trained on images. We also showcase a variety of stylistic image captioning models that were trained using no image data and no human-curated language data, but instead text data from books, the web, or language models.
Deep Reinforcement Learning with Function Properties in Mean Reversion Strategies
Jan 12, 2021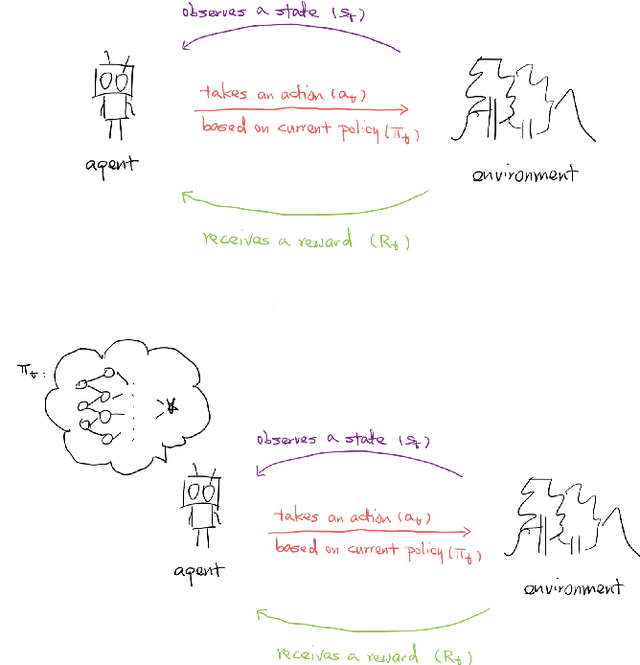


With the recent advancement in Deep Reinforcement Learning in the gaming industry, we are curious if the same technology would work as well for common quantitative financial problems. In this paper, we will investigate if an off-the-shelf library developed by OpenAI can be easily adapted to mean reversion strategy. Moreover, we will design and test to see if we can get better performance by narrowing the function space that the agent needs to search for. We achieve this through augmenting the reward function by a carefully picked penalty term.