 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRadZero: Similarity-Based Cross-Attention for Explainable Vision-Language Alignment in Radiology with Zero-Shot Multi-Task Capability
Apr 10, 2025Recent advancements in multi-modal models have significantly improved vision-language alignment in radiology. However, existing approaches struggle to effectively utilize complex radiology reports for learning, rely on low-resolution images, and offer limited interpretability in attention mechanisms. To address these challenges, we introduce RadZero, a novel similarity-based cross-attention framework for vision-language alignment in radiology with zero-shot multi-task capability. RadZero leverages large language models to extract minimal semantic sentences from radiology reports and employs a multi-positive contrastive learning strategy to effectively capture relationships between images and multiple relevant textual descriptions. It also utilizes a pre-trained vision encoder with additional trainable Transformer layers, allowing efficient high-resolution image processing. By computing similarity between text embeddings and local image patch features, RadZero enables zero-shot inference with similarity probability for classification and pixel-level cross-modal similarity maps for grounding and segmentation. Experimental results on public chest radiograph benchmarks show that RadZero outperforms state-of-the-art methods in zero-shot classification, grounding, and segmentation. Furthermore, cross-modal similarity map analysis highlights its potential for improving explainability in vision-language alignment. Additionally, qualitative evaluation demonstrates RadZero's capability for open-vocabulary semantic segmentation, further validating its effectiveness in medical imaging.
Leveraging LLMs for Multimodal Retrieval-Augmented Radiology Report Generation via Key Phrase Extraction
Apr 10, 2025
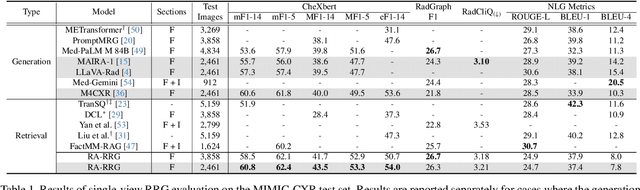


Automated radiology report generation (RRG) holds potential to reduce radiologists' workload, especially as recent advancements in large language models (LLMs) enable the development of multimodal models for chest X-ray (CXR) report generation. However, multimodal LLMs (MLLMs) are resource-intensive, requiring vast datasets and substantial computational cost for training. To address these challenges, we propose a retrieval-augmented generation approach that leverages multimodal retrieval and LLMs to generate radiology reports while mitigating hallucinations and reducing computational demands. Our method uses LLMs to extract key phrases from radiology reports, effectively focusing on essential diagnostic information. Through exploring effective training strategies, including image encoder structure search, adding noise to text embeddings, and additional training objectives, we combine complementary pre-trained image encoders and adopt contrastive learning between text and semantic image embeddings. We evaluate our approach on MIMIC-CXR dataset, achieving state-of-the-art results on CheXbert metrics and competitive RadGraph F1 metric alongside MLLMs, without requiring LLM fine-tuning. Our method demonstrates robust generalization for multi-view RRG, making it suitable for comprehensive clinical applications.
M4CXR: Exploring Multi-task Potentials of Multi-modal Large Language Models for Chest X-ray Interpretation
Aug 29, 2024



The rapid evolution of artificial intelligence, especially in large language models (LLMs), has significantly impacted various domains, including healthcare. In chest X-ray (CXR) analysis, previous studies have employed LLMs, but with limitations: either underutilizing the multi-tasking capabilities of LLMs or lacking clinical accuracy. This paper presents M4CXR, a multi-modal LLM designed to enhance CXR interpretation. The model is trained on a visual instruction-following dataset that integrates various task-specific datasets in a conversational format. As a result, the model supports multiple tasks such as medical report generation (MRG), visual grounding, and visual question answering (VQA). M4CXR achieves state-of-the-art clinical accuracy in MRG by employing a chain-of-thought prompting strategy, in which it identifies findings in CXR images and subsequently generates corresponding reports. The model is adaptable to various MRG scenarios depending on the available inputs, such as single-image, multi-image, and multi-study contexts. In addition to MRG, M4CXR performs visual grounding at a level comparable to specialized models and also demonstrates outstanding performance in VQA. Both quantitative and qualitative assessments reveal M4CXR's versatility in MRG, visual grounding, and VQA, while consistently maintaining clinical accuracy.