 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging LLMs for Multimodal Retrieval-Augmented Radiology Report Generation via Key Phrase Extraction
Paper and Code

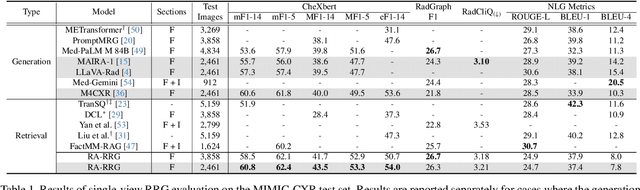


Automated radiology report generation (RRG) holds potential to reduce radiologists' workload, especially as recent advancements in large language models (LLMs) enable the development of multimodal models for chest X-ray (CXR) report generation. However, multimodal LLMs (MLLMs) are resource-intensive, requiring vast datasets and substantial computational cost for training. To address these challenges, we propose a retrieval-augmented generation approach that leverages multimodal retrieval and LLMs to generate radiology reports while mitigating hallucinations and reducing computational demands. Our method uses LLMs to extract key phrases from radiology reports, effectively focusing on essential diagnostic information. Through exploring effective training strategies, including image encoder structure search, adding noise to text embeddings, and additional training objectives, we combine complementary pre-trained image encoders and adopt contrastive learning between text and semantic image embeddings. We evaluate our approach on MIMIC-CXR dataset, achieving state-of-the-art results on CheXbert metrics and competitive RadGraph F1 metric alongside MLLMs, without requiring LLM fine-tuning. Our method demonstrates robust generalization for multi-view RRG, making it suitable for comprehensive clinical applications.